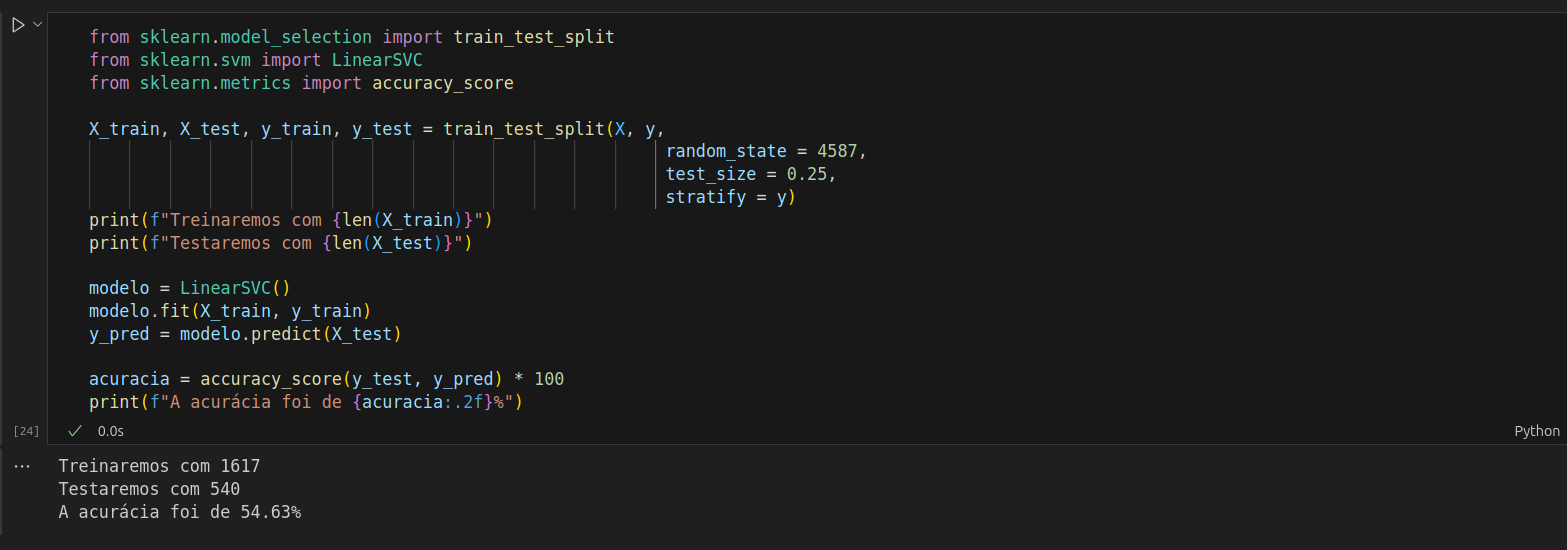
A acurácia de base deu a mesma mas a acurácia do modelo ficou difrente:
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

A acurácia de base deu a mesma mas a acurácia do modelo ficou difrente:


Olá, William, tudo bem?
No código da aula, a SEED utilizada é 20. No seu código, a SEED utilizada é 4587. A mudança na SEED altera a forma como os dados são divididos entre treino e teste, o que impacta diretamente no resultado do modelo. Para garantir que você obtenha os mesmos resultados da aula, sugiro que você defina a SEED com o mesmo valor utilizado na aula (20).
Abaixo deixo o código do curso:
from sklearn.model_selection import train_test_split
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
SEED = 20
treino_x, teste_x, treino_y, teste_y = train_test_split(x, y,
random_state = SEED,
stratify = y)
print(f"Treinaremos com {len(treino_x)}")
print(f"Testaremos com {len(teste_x)}")
modelo = LinearSVC()
modelo.fit(treino_x, treino_y)
previsoes = modelo.predict(teste_x)
acuracia = accuracy_score(teste_y, previsoes) * 100
print(f"A acurácia foi de {acuracia:.2f}%")
Depois de fazer as alterações, reinicie o notebook, seguindo estes passos:
No menu de ferramentas do Google Colaboratory, clicar em "Ambientes de execução";
Selecionar a opção "Reiniciar sessão e executar tudo".
Para realizar essas etapas, você pode acompanhar a imagem abaixo:

Espero que isso ajude! Se tiver mais alguma dúvida, pode me perguntar.