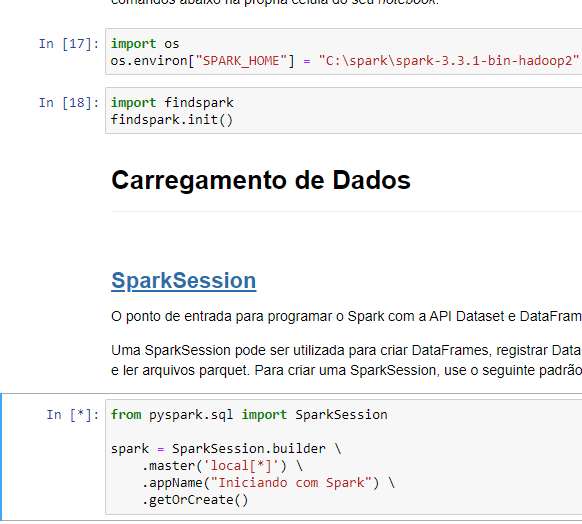
Estou tentando rodar o SparkSession.builder localmente no jupyter mas não finaliza nunca, não sei qual é o problema.
Python: 3.10.4; Java: 1.8.0_51 Hadoop: 2.7 Spark: 3.3.1
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Estou tentando rodar o SparkSession.builder localmente no jupyter mas não finaliza nunca, não sei qual é o problema.
Python: 3.10.4; Java: 1.8.0_51 Hadoop: 2.7 Spark: 3.3.1


Falar mano, qual o seu sistema operacional que você esta radando é windows ou linux?
Windows!
Você conseguiu resolver esse problema?
Ainda não
Borar lá,
Você já tem instalando, 1 - Java versão mais recente? - para verificar se o java está instalando na sua maquina no terminal 'java -version' 2 - o python a versão atual? - para verificar se o java está instalando na sua maquina no terminal 'python -version' 3 - você baixou o arquivo do spark 3.2.3 - > https://www.apache.org/dyn/closer.lua/spark/spark-3.2.3/spark-3.2.3-bin-hadoop2.7.tgz e extraiu para uma pasta especifica exemplo 'c:\spark' 4 - basta digitar o comando pip install findspark no terminal 5 - você vai fazer o download do arquivo winutils - > https://github.com/steveloughran/winutils/raw/master/hadoop-2.7.1/bin/winutils.exe feito isso , você vai em 'c:\spark' dentro do 'c:\spark' você vai entrar nela e dentro da pasta do 'park' vc terá que criar duas subpastas exemplo 'c:\spark\hadoop\bin' e dentro da pasta 'bin' você vai cópia o arquivo baixando no passo 4, ficara assim 'c:\spark\hadoop\bin\winutils.exe'
fiz esse procedimentos no windows e deu certo" no meu windows 11.