
Na aula, é passada a demanda para identificar a idade dos 20% mais jovens. Pela lógica passada em aul, chega-se ao números de 2218 colaboradores que seriam os mais jovens com idade máxima de 25.

Porém, eu pensei que utilizar a função quantile passando 0.20 também me daria o mesmo resultado. E de fato, quando uso quantile na coluna idade, obtenho a mesma idade máxima de 25 gerada no dataset "idades_qualificados". Porém, quando aplico o filtro em colaboradores para conferir se a quantidade de registros seria a mesma de 2218, obtenho um número diferente de registros: 2274.
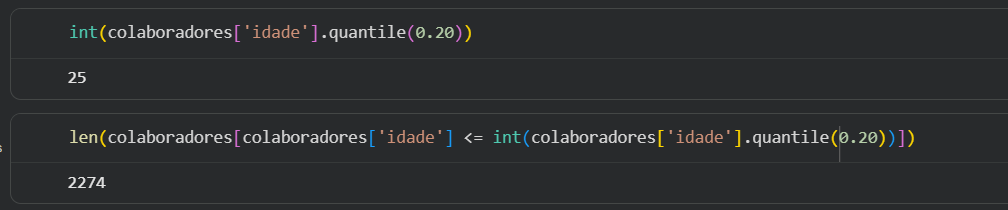
Minha dúvida é: quando usar e quando não usar quantile. Por que pelo enunciado do problema da aula, eu pensei que quantile resolveria. Mas, eu obtive um valor diferente daquele calculado pela instrutora.

