
resolvi fazer o desafio que o instrutor propôs, porém fazendo os gráficos de 2 regiões na mesma figura: sul e sudeste. fiz o seguinte código:
df_pib_sul = df_pib.query('regiao == "Sul"')[['sigla_uf', 'pib']]
df_pib_sul = df_pib_sul.groupby('sigla_uf').sum().sort_values('pib', ascending = False)
df_pib_sudeste = df_pib.query('regiao == "Sudeste"')[['sigla_uf', 'pib']]
df_pib_sudeste = df_pib_sudeste.groupby('sigla_uf').sum().sort_values('pib', ascending = False)
fig, axs = plt.subplots(1, 2, figsize=(14,6))
cores_sul = [AZUL3, LARANJA1, VERDE1]
cores_sudeste = [AZUL3, LARANJA1, VERDE1, AZUL5]
plt.suptitle('PIB por estados', fontsize = 18, color = CINZA1, ha = 'right', x = 0.5, y = 1.05)
#GRÁFICO 1 - REGIÃO SUL
ptc, text, _ = axs[0].pie(data = df_pib_sul, x = 'pib', labels = df_pib_sul.index, autopct = '%.1f%%',
pctdistance = 0.6, textprops = {'size':12, 'fontweight': 'bold', 'color': BRANCO},
colors = cores_sul)
axs[0].annotate('Região Sul', xy = (50, 350), size = 12, xycoords = 'axes points',
bbox = dict(boxstyle = 'round', fc = BRANCO,ec = CINZA3))
# GRÁFICO 2 - REGIÃO SUDESTE
ptc, text, _ = axs[1].pie(data = df_pib_sudeste, x = 'pib', labels = df_pib_sudeste.index, autopct = '%.1f%%',
pctdistance = 0.6, textprops = {'size':12, 'fontweight': 'bold', 'color': BRANCO},
colors = cores_sudeste)
axs[1].annotate('Região Sudeste', xy = (50, 350), size = 12, xycoords = 'axes points',
bbox = dict(boxstyle = 'round', fc = BRANCO,ec = CINZA3))
for i, p in enumerate(ptc):
text[i].set_color(p.get_facecolor())
plt.show()
e me retornou a seguinte imagem:
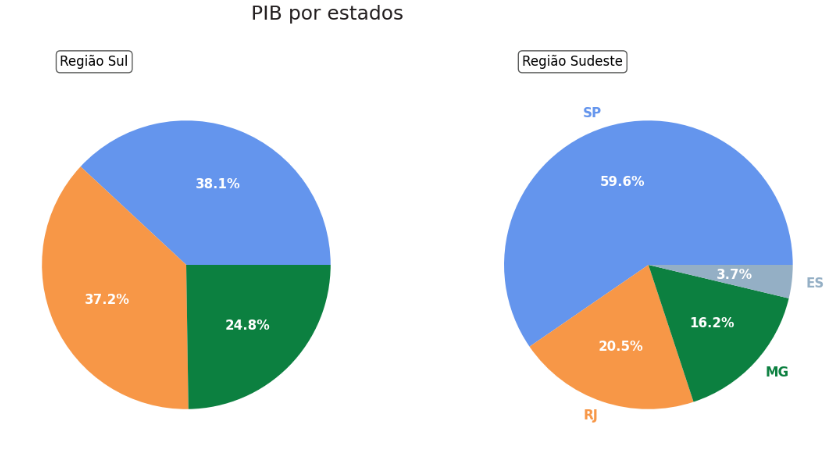 porque não estão aparecendo as labels do primeiro gráfico? acredito que seja por conta da diferença do número de colunas nos dataframes, mas como faço pra corrigir o código?
porque não estão aparecendo as labels do primeiro gráfico? acredito que seja por conta da diferença do número de colunas nos dataframes, mas como faço pra corrigir o código?

