Oi, boa tarde!
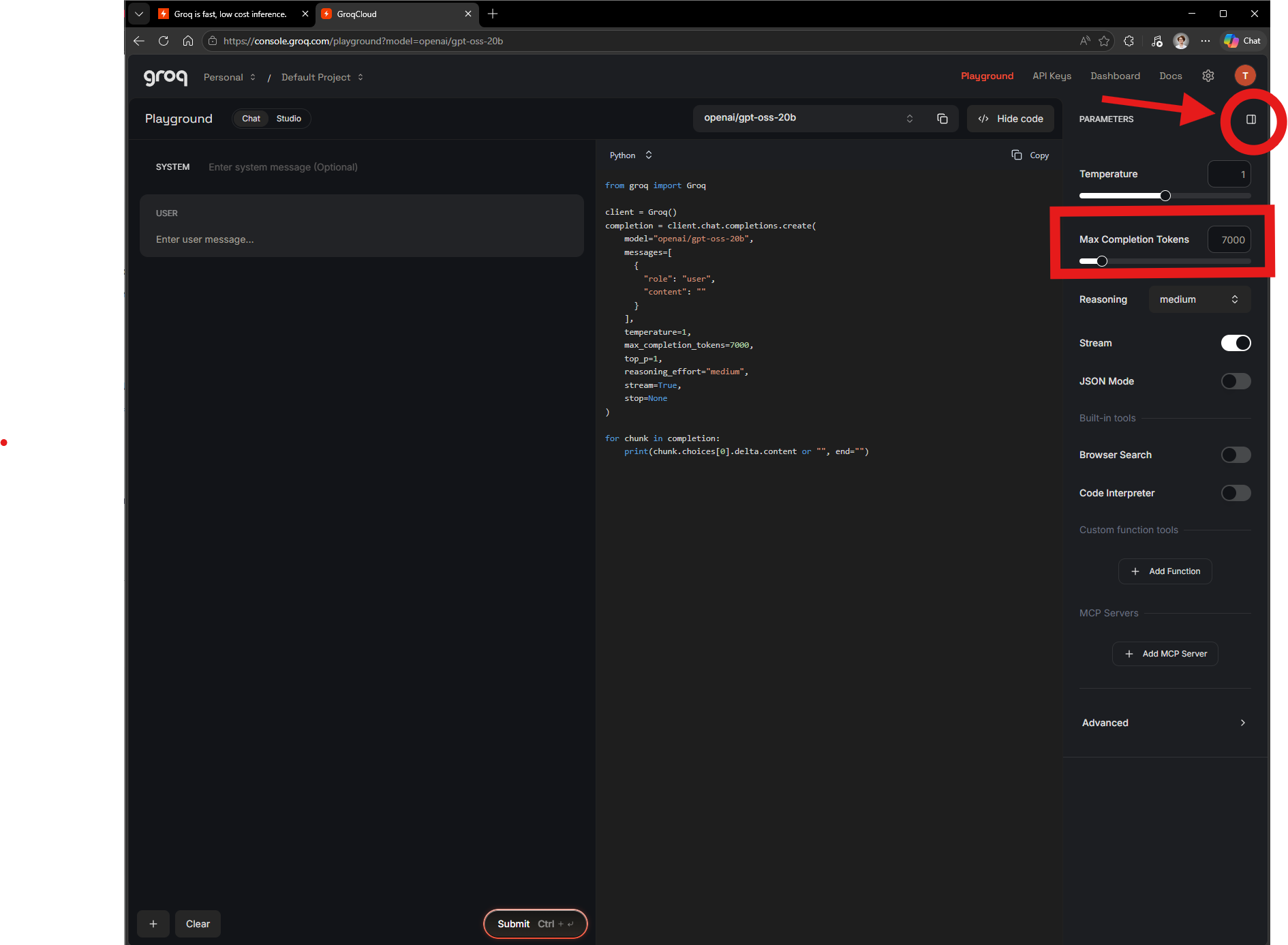
Alguém poderia me ajudar a usar o Groq, estou tendo essa mensagem de retorno e não consegui testar.
No site do Groq, consegui apenas a criar uma API Key free.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Oi, boa tarde!
Alguém poderia me ajudar a usar o Groq, estou tendo essa mensagem de retorno e não consegui testar.
No site do Groq, consegui apenas a criar uma API Key free.


Olá Thayane! Tudo bem?
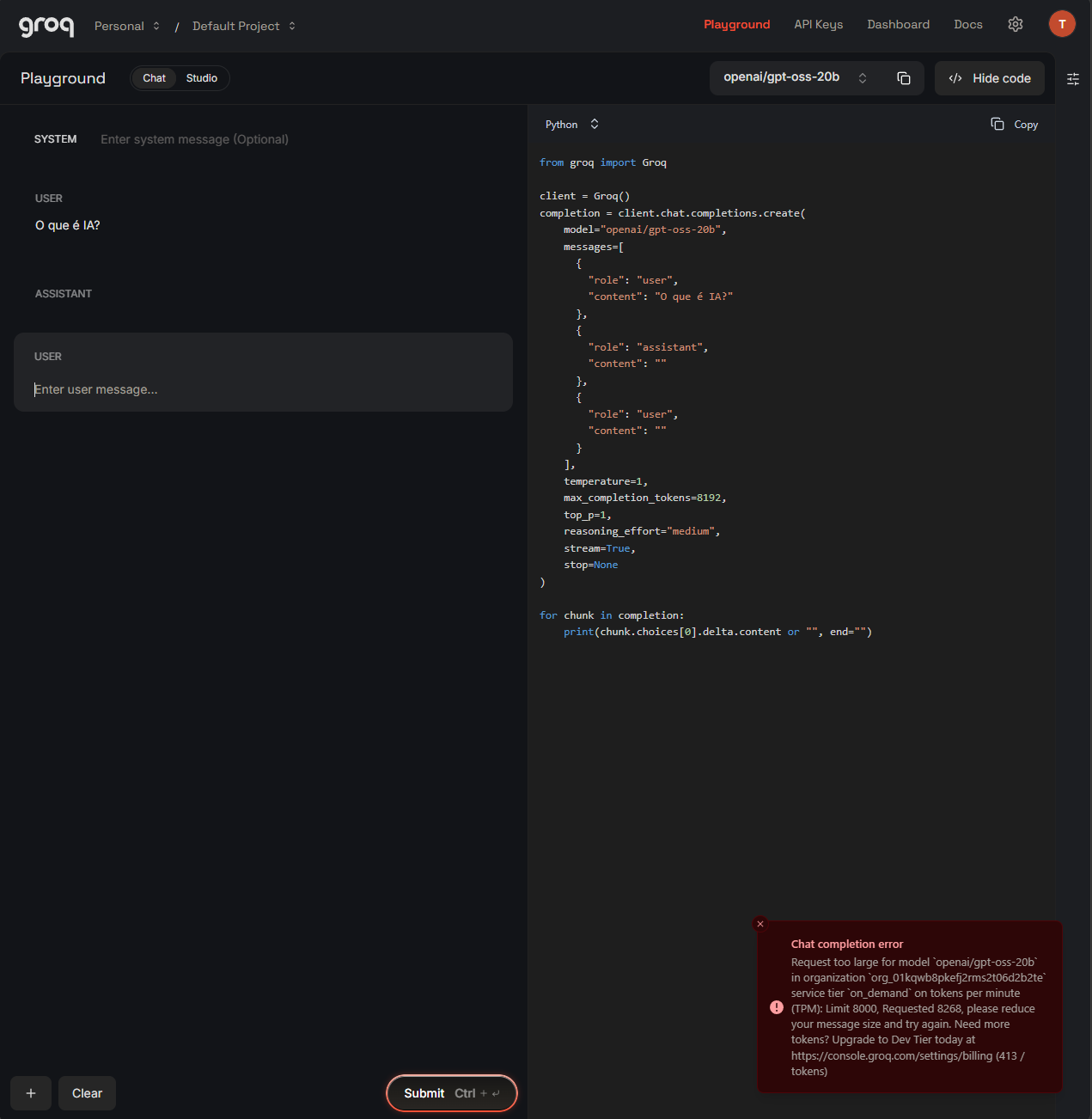
O erro que você recebeu foi o:
Request too large for model openai/gpt-oss-20b in organization org_01kqwb8pkefj2rms2t06d2b2te service tier on_demand on tokens per minute (TPM): Limit 8000, Requested 8268, please reduce your message size and try again. Need more tokens? Upgrade to Dev Tier today at https://console.groq.com/settings/billing (413 / tokens)
Por que isso aconteceu?
A Groq permite 8.000 tokens por minuto para esse modelo (openai/gpt-oss-20b), mas segundo a mensagem de erro, a sua requisição solicitou 8268 tokens. O culpado principal é o parâmetro max_completion_tokens=8192. Quando você define esse valor, o sistema "reserva" essa capacidade para a sua resposta, o que já estoura o seu limite de 8.000 antes mesmo de começar.
Como ajustar o código:
Para resolver e manter o código o mais próximo possível da aula, basta reduzir o valor de max_completion_tokens para um número abaixo do seu limite de 8.000.
No código abaixo utilizei 7000:
Python
os.environ["GROQ_API_KEY"] = userdata.get('Groq_API_Key')
from groq import Groq
client_groq = Groq()
completion = client_groq.chat.completions.create(
model="openai/gpt-oss-20b",
messages=[
{
"role": "user",
"content": "Sol?"
}
],
temperature=1,
# Ajustado de 8192 para 7000 para não estourar o limite de 8000 da conta
max_completion_tokens=7000,
stream=True,
stop=None
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")
💡Dica alternativa:
Você pode também testar outros modelos, como o llama-3.3-70b-versatile, que possui um limite maior (12.000). Neste caso, você não precisaria ajustar o max_completion_tokens. Apenas ajustaria o model.
Abaixo deixo um link com outros possíveis modelos e seus respectivos limites.
O link está em inglês, mas você poderá utilizar a tradução automática do navegador
Me conta: após fazer uma das soluções acima, você conseguiu prosseguir com o projeto?
Bom dia,
Obrigada pela resposta, Monalisa!
Como eu estava testando o site do Groq, não encontrei onde pudesse alterar o código, mas pesquisando, vi que tem um botão onde podemos alterar algumas configurações, e nessa parte tem um campo "Max Completion Tokens", e eu diminui o valor dele para abaixo de 8000, e deu certo testar!