
Eu não consigo achar o problema, estou quebrando a cabeça há bastante tempo, mas meu objetivo é apenas selecionar 'Sudeste' e 'Norte' (no eixo x) para fazer a comparação entre o aproveitamento em Linguagens e códigos no enem (eixo y). Alguém pode por favor me ajudar?
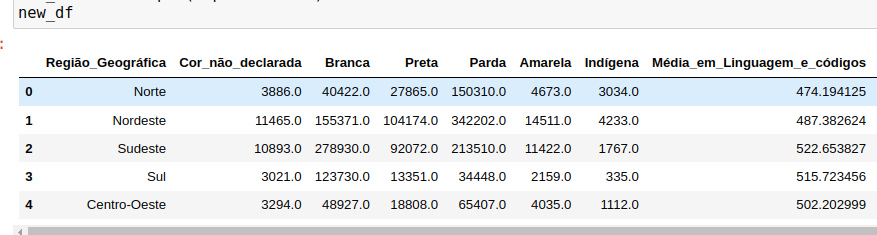
Gráfico comparando o aproveitamento em LINGUAGEM E CÓDIGOS entre a região SUDESTE e NORTE
x = new_df.Média_em_Linguagem_e_códigos.mean()
y = new_df[(new_df["Região_Geográfica"] == "Norte")]
y2 = new_df[(new_df["Região_Geográfica"] == "Sudeste")]
fig, varx = plt.subplots()
varx.plot(x, y, label='Notas região Norte')
varx.plot(x, y2, label='Notas região Sudeste')
varx.set_title('Comparação das notas em LINGUAGEM E CÓDIGOS entre as regiões Norte e Sudeste')
varx.set_xlabel('Regiões')
varx.set_ylabel('Média em Linguagem e Códigos')
varx.set_legend()
varx.show()Erro:
ValueError: x and y must have same first dimension, but have shapes (1,) and (0, 10)Mesmo mudando a maneira de agrupar(Utilizando o groupby) os dados:
# Gráfico comparando o aproveitamento em LINGUAGEM E CÓDIGOS entre a região SUDESTE e NORTE
x = new_df.Média_em_Linguagem_e_códigos.mean()
# y = new_df[(new_df["Região_Geográfica"] == "Norte")]
y = new_df.groupby('Região_Geográfica')['Norte']
# y2 = new_df[(new_df["Região_Geográfica"] == "Sudeste")]
y2 = new_df.groupby('Região_Geográfica')['Sudeste']
fig, varx = plt.subplots()
varx.plot(x, y, label='Notas região Norte')
varx.plot(x, y2, label='Notas região Sudeste')
varx.set_title('Comparação das notas em LINGUAGEM E CÓDIGOS entre as regiões Norte e Sudeste')
varx.set_xlabel('Regiões')
varx.set_ylabel('Média em Linguagem e Códigos')
varx.set_legend()
varx.show()O erro persiste:
KeyError: 'Column not found: Norte'


