Rafael,
Antes de tudo, nós precisamos pensar em como está a estrutura do JSON.
Se você tentar carregar o JSON da API das frutas, diretamente sem fazer normalização o resultado será o seguinte:
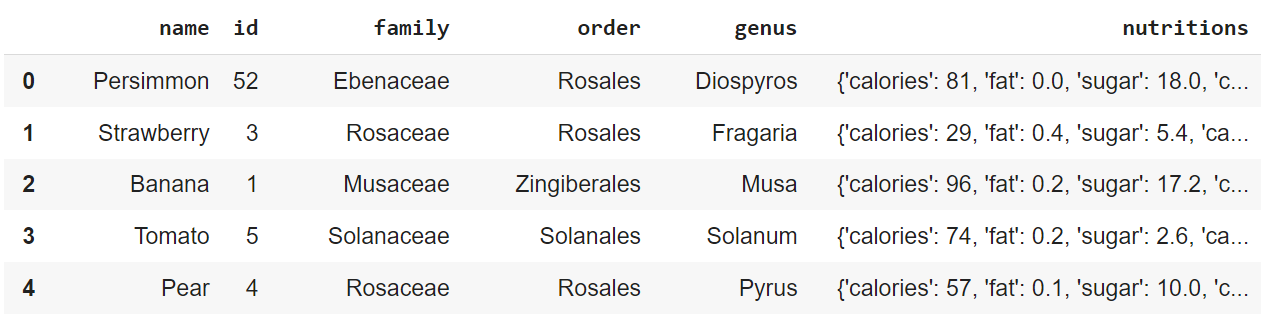 Note que temos a coluna "Nutritions" com dados dentro de um dicionário, contendo chaves e valores para cada característica nutricional (calories, fat, sugar...)
Note que temos a coluna "Nutritions" com dados dentro de um dicionário, contendo chaves e valores para cada característica nutricional (calories, fat, sugar...)
Nesse caso, em específico, se usarmos a função json_normalize(), ela vai automaticamente transformar cada uma das chaves e valores em colunas e linhas:

Como o nome da coluna original era "nutritions" ela usa essa palavra como um prefixo na criação das novas colunas normalizadas.
Já a normalização com os parâmetros record_path e meta é indicada quando temos estruturas mais complexas em json, como objetos dentro de outros objetos, como listas de dicionários, por exemplo.
No código que você mandou na primeira mensagem, não há necessidade da criação de um DataFrame a partir do resultado da requisição. Como o resultado já é uma lista de dicionários (cada dicionário representa uma fruta), não é necessário criar um DataFrame a partir desses dados.
Então, bastaria o código abaixo para funcionar:
import requests
import json
import pandas as pd
dados_frutas = requests.get('https://fruityvice.com/api/fruit/all')
resultado = json.loads(dados_frutas.text)
fruits_normalizados = pd.json_normalize(resultado)
fruits_normalizados
Espero que isso esclareça a abordagem para normalizar esse JSON da API das frutas.
Bons estudos!


