
Boa tarde!
Na aula sobre padronização / normalização dos dados para construção do modelo de PCA o instrutor utilizou a ferramenta StandardScaler para efetuar os cálculos e transformações necessárias. Minha dúvida com respeito a essa ferramenta é a seguinte: como são cálculados a média e o desvio-padrão por parte do algoritmo?
Na seção "para saber mais" incluída logo após a aula, foram apresentadas as seguintes definições:
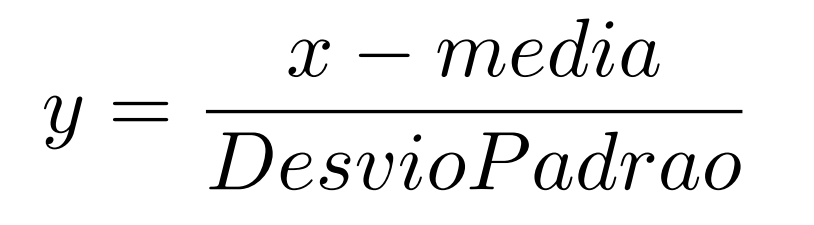
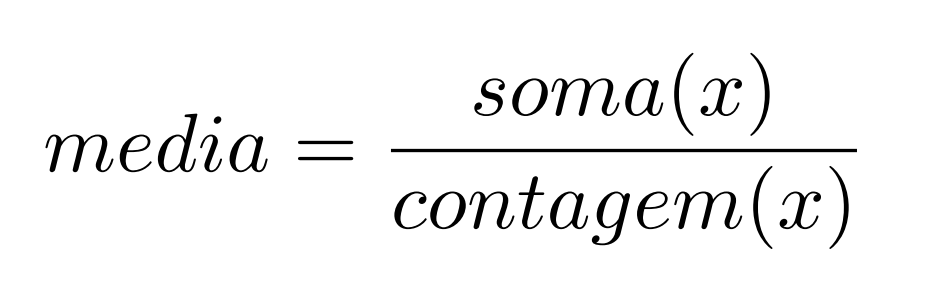
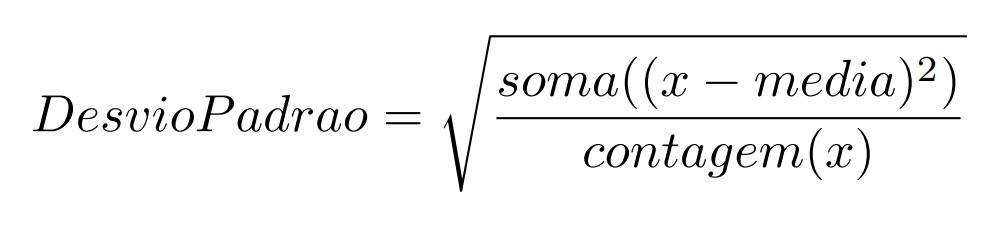
mas eu não estou conseguindo entender quais dados estão sendo utilizados para calcular a média e o desvio-padrão.
De acordo com as definições apresentadas, meu entendimento diz que essas quantidades devem ser calculadas para cada feature. Ou seja, cada feature teria uma média e um desvio-padrão correspondente para que a padronização pudesse ser feita.
Entretanto eu fiz um teste no python apenas para verificar se o raciocínio estava correto, e o resultado obtido não foi consistente com a saída do algoritmo. Fiz os seguintes procedimentos:
Inicialmente, verifiquei o comportamento das features originais e das features escaladas e resolvi aplicar os cálculos manualmente para a primeira feature do select abaixo. Na imagem, podemos ver que essa feature assume valores 0 ou 1, e que os valores reescalados são ~2.68 quando o valor original é 1 e ~0.0 quando o valor original é 0.
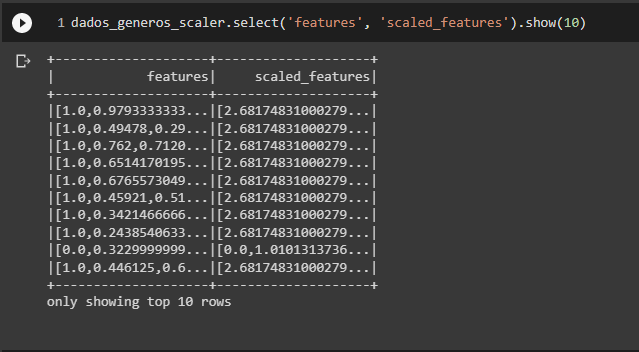
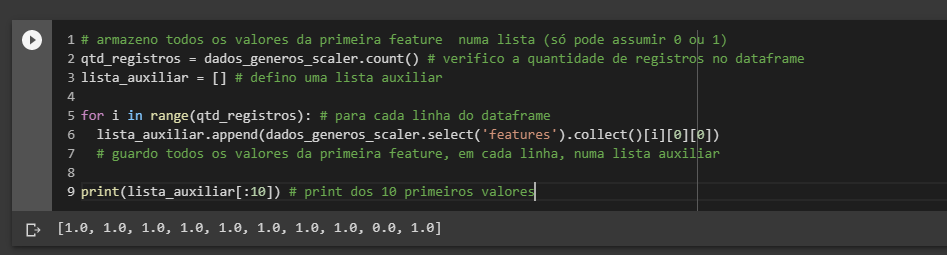
Em vista disso, o que fiz para testar a aplicação do algoritmo foi, inicialmente, armazenar todos os valores originais dessa feature em uma lista auxiliar, tal como descrito no código a seguir
Por fim, efetuei o cálculo dos parâmetros estatísticos e apliquei a definição da padronização, contudo obtive um resultado incorreto
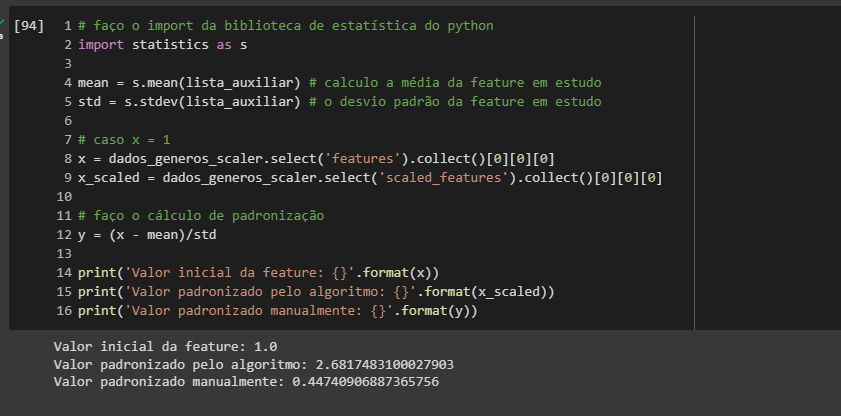
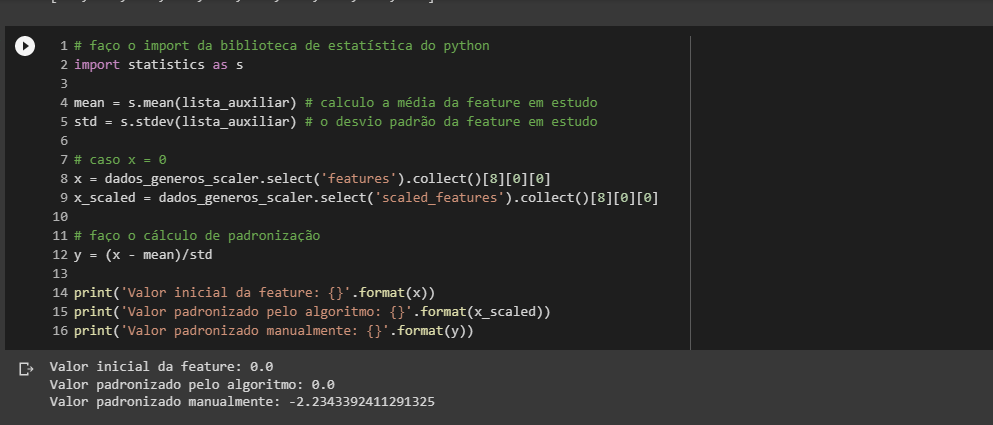 Por conta desses resultados, não estou conseguindo compreender como o algoritmo StandardScaler funciona. Tentei buscar a documentação, mas também não encontrei detalhes sobre como esses parâmetros estatísticos são calculados pelo algoritmo.
Por conta desses resultados, não estou conseguindo compreender como o algoritmo StandardScaler funciona. Tentei buscar a documentação, mas também não encontrei detalhes sobre como esses parâmetros estatísticos são calculados pelo algoritmo.

