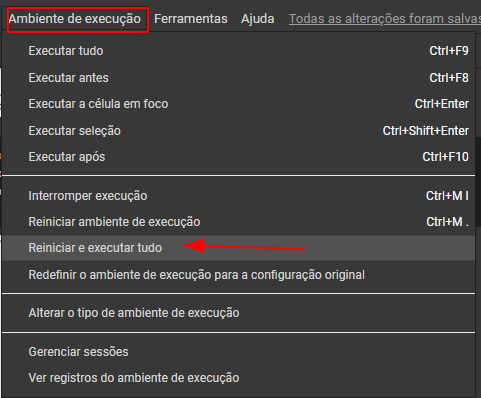
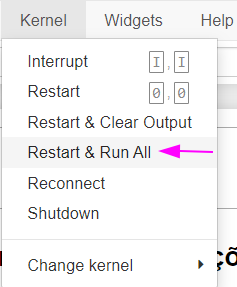
O DF1 não está rodando, os outros estão funcionando normalmente, como solucionar? grato.
df1[df1 > 0] = 'A'
df1---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-83-3cbbcb6a4b10> in <module>
----> 1 df1[df1 > 0] = 'A'
2 df1
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\ops\common.py in new_method(self, other)
63 other = item_from_zerodim(other)
64
---> 65 return method(self, other)
66
67 return new_method
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\arraylike.py in __gt__(self, other)
43 @unpack_zerodim_and_defer("__gt__")
44 def __gt__(self, other):
---> 45 return self._cmp_method(other, operator.gt)
46
47 @unpack_zerodim_and_defer("__ge__")
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\frame.py in _cmp_method(self, other, op)
5969
5970 # See GH#4537 for discussion of scalar op behavior
-> 5971 new_data = self._dispatch_frame_op(other, op, axis=axis)
5972 return self._construct_result(new_data)
5973
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\frame.py in _dispatch_frame_op(self, right, func, axis)
6006 if not is_list_like(right):
6007 # i.e. scalar, faster than checking np.ndim(right) == 0
-> 6008 bm = self._mgr.apply(array_op, right=right)
6009 return type(self)(bm)
6010
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs)
423 try:
424 if callable(f):
--> 425 applied = b.apply(f, **kwargs)
426 else:
427 applied = getattr(b, f)(**kwargs)
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in apply(self, func, **kwargs)
376 """
377 with np.errstate(all="ignore"):
--> 378 result = func(self.values, **kwargs)
379
380 return self._split_op_result(result)
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in comparison_op(left, right, op)
241
242 elif is_object_dtype(lvalues.dtype):
--> 243 res_values = comp_method_OBJECT_ARRAY(op, lvalues, rvalues)
244
245 else:
C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\ops\array_ops.py in comp_method_OBJECT_ARRAY(op, x, y)
53 result = libops.vec_compare(x.ravel(), y.ravel(), op)
54 else:
---> 55 result = libops.scalar_compare(x.ravel(), y, op)
56 return result.reshape(x.shape)
57
pandas\_libs\ops.pyx in pandas._libs.ops.scalar_compare()
TypeError: '>' not supported between instances of 'str' and 'int