
Consultas simples pelo Spring já me deram dor de cabeça algumas vezes, mas superei e agora eu tenho um novo problemão, preciso utilizar uma Exibição de um Banco SqlServer, e ainda preciso também utilizar o Group By para trazer informações precisas para um relatório, isso é feito para otimizar a resposta para o usuário. A seguinte consulta:
SELECT Descricao,
Expr1,
SUM(ValorApurado) as ValorApurado,
Count(Descricao) as Quantidade,
SUM(QuantidadeEixo) as QuantidadeEixo
FROM
VE_RelResumoArrecadacaoIsentoDiversos
GRoup by Descricao,
Expr1Pelo que eu sei do Spring preciso criar uma entidade para receber esses dados, mas o problema está no momento em que o Spring me diz que não tem um id para a tabela ai eu me perco.
Abaixo uma Classe do Spring com uma Query Básica:
public interface RepoVE_RelRecarga extends JpaRepository<VE_RelRecarga, Integer> {
@Query(value = "select * from VE_RelRecarga where IdConta = ?1 AND DataOperacao > ?2 AND DataOperacao < ?3", nativeQuery = true)
ArrayList<VE_RelRecarga> findAllRecargas(int idConta, Timestamp dataInicio, Timestamp dataFinal);
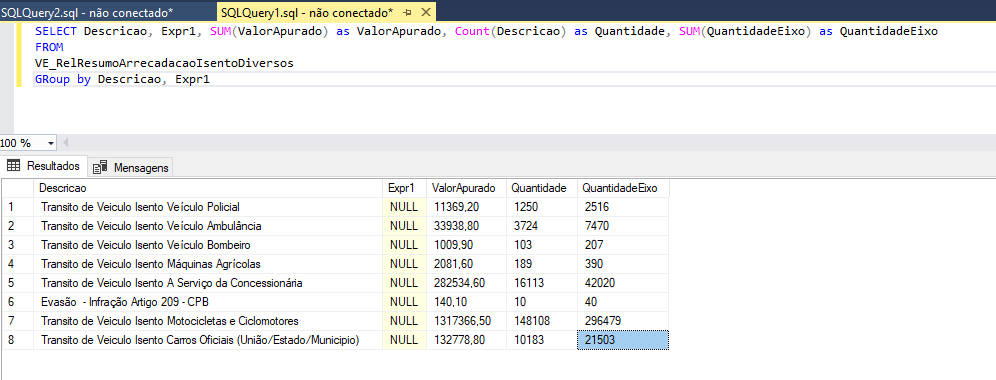
}Essa query acima busca dados a partir de uma data, esses dados tem um ID então são normalmente implantados em um ArrayList, agora quando fizermos uma query com um Group By no final não dados com ID que retornaram: Exemplo na imagem em anexo abaixo:
Preciso saber como procedo no Spring Data para Implantar esses dados em uma Classe no java.

