 ``
``
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

``


Olá, Ivaney. Como vai?
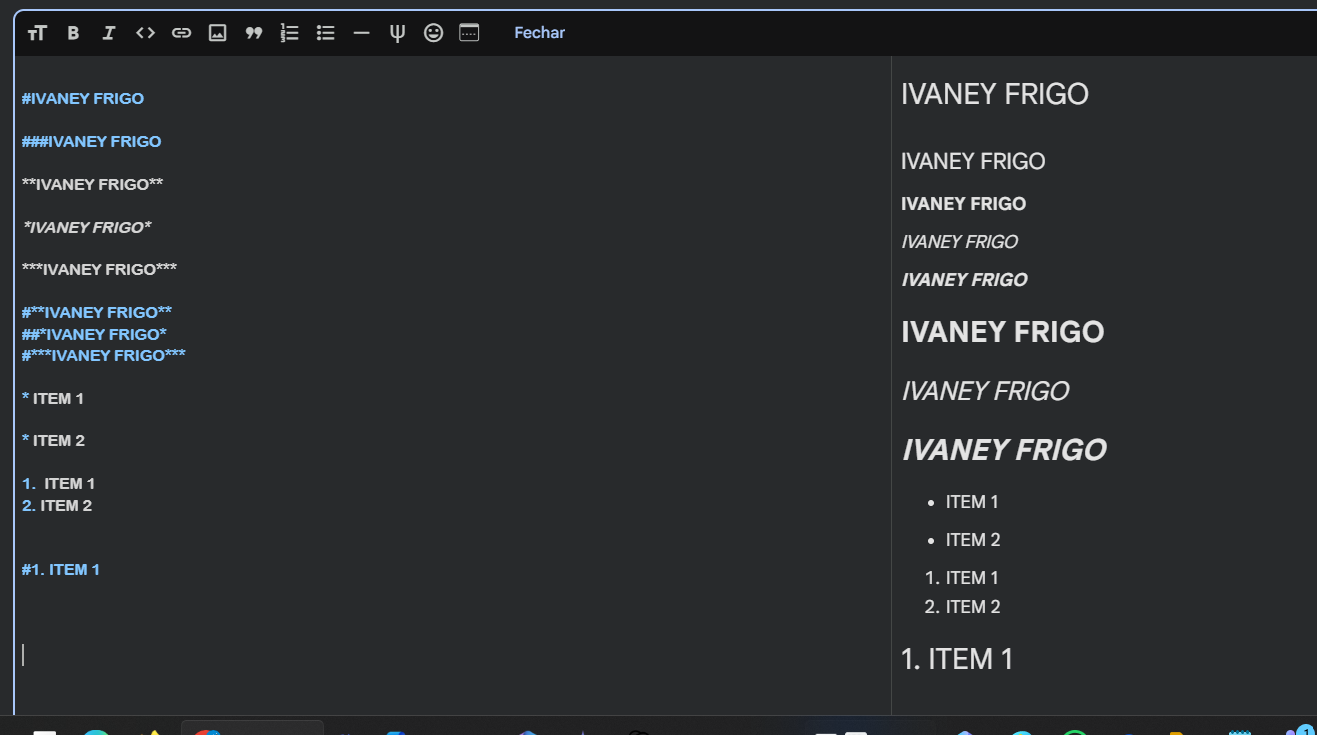
Excelente demonstração prática! O Markdown é uma linguagem de marcação leve e essencial para qualquer pessoa que trabalha com Data Science, pois é a base para documentar notebooks (como no Jupyter ou Google Colab) e repositórios no GitHub.
Pela sua imagem, vejo que você explorou muito bem como a combinação de símbolos altera a hierarquia e o estilo do texto. Para agregar ainda mais valor ao seu estudo, aqui estão algumas dicas de boas práticas sobre o que você testou:
# (H1) deve ser reservado para o título principal do documento, enquanto o ## (H2) e o ### (H3) organizam as seções e subseções. Isso ajuda não só na leitura, mas também na criação automática de sumários em notebooks.***TEXTO***, que resulta em negrito e itálico simultâneos. No dia a dia de análise de dados, isso é ótimo para destacar termos técnicos que também são importantes.*) e ordenadas (1.). Uma dica importante é que o Markdown permite criar subitens apenas adicionando espaços antes do marcador:* Item Principal
* Subitem (identado com 4 espaços ou tab)
Dominar essa formatação é o que separa um código funcional de um projeto de Data Science profissional. Um notebook bem documentado permite que outras pessoas (ou você mesmo no futuro) entendam o raciocínio por trás de cada linha de código Python.
Continue praticando essas marcações nos seus projetos de aula para transformar seus estudos em relatórios claros e visualmente organizados!
Espero que possa ter lhe ajudado!