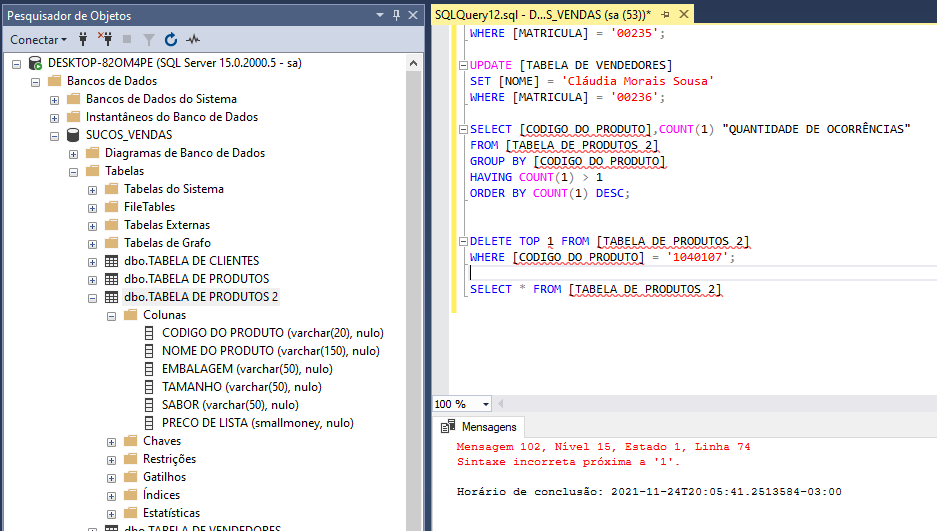
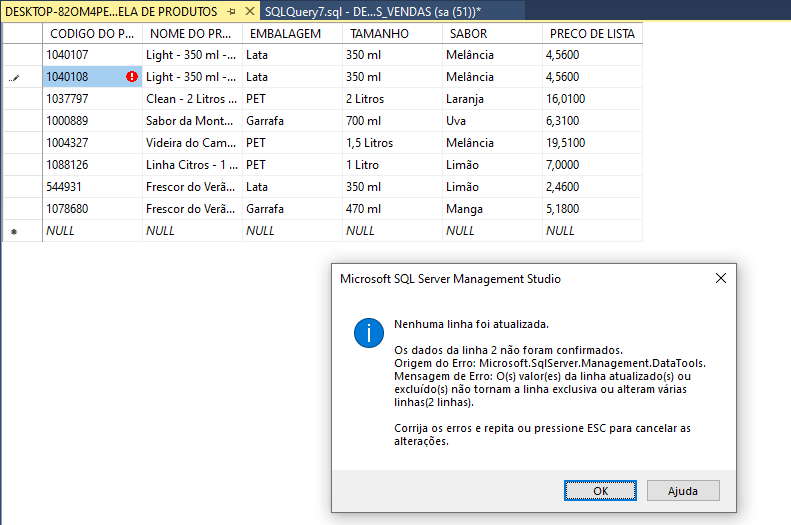
 Quero saber uma forma de excluir uma linha que tem todos os itens duplicados, uma vez que eu inseri duas vezes o mesmo registro e se eu fizer um update vai atualizar as duas linhas e se eu deletar irá remover os dois registros, tem como remover somente um registro?
Quero saber uma forma de excluir uma linha que tem todos os itens duplicados, uma vez que eu inseri duas vezes o mesmo registro e se eu fizer um update vai atualizar as duas linhas e se eu deletar irá remover os dois registros, tem como remover somente um registro?