import pandas as pd
# Dados das pessoas
dados = {
'Pessoa': ['Ana', 'Bruno', 'Carla', 'Daniel', 'Eduarda', 'Felipe', 'Gabriela', 'Henrique'],
'Peso': [50, 80, 70, 95, 60, 110, 45, 130],
'Altura': [1.60, 1.75, 1.68, 1.80, 1.55, 1.90, 1.50, 1.85]
}
# Criando o DataFrame
df_saude = pd.DataFrame(dados)
# Criar uma função chamada categoriza_imc que classifique o IMC nas seguintes categorias:
def categoriza_imc(imc):
if imc < 18.5:
return 'Abaixo do peso'
elif imc <= 24.9:
return 'Peso normal'
elif imc <= 29.9:
return 'Sobrepeso'
elif imc <= 34.9:
return 'Obesidade grau 1'
elif imc <= 39.9:
return 'Obesidade grau 2'
else:
return 'Obesidade grau 3'
# Calcular o IMC para cada pessoa usando a fórmula:
df_saude['IMC'] = df_saude['Peso'] / (df_saude['Altura'] ** 2)
df_saude['Categoria_IMC'] = df_saude['IMC'].apply(categoriza_imc)
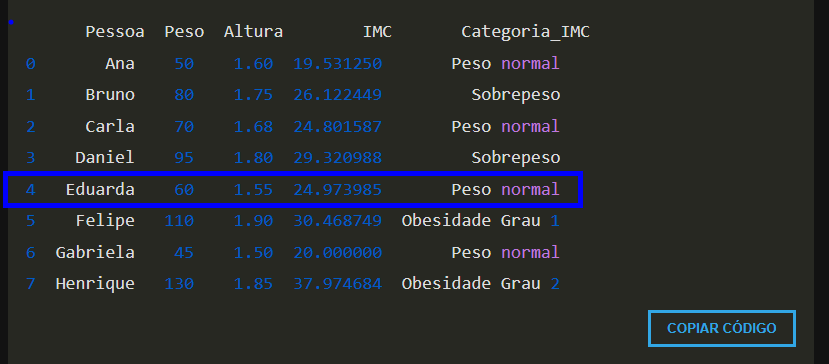
print(df_saude[['Pessoa', 'Peso', 'Altura', 'IMC','Categoria_IMC']])
Nota, o resultado da Eduarda arredonda e o resultado dela fica diferente da Saída esperada.