Oii, Frederico! Tudo bem?
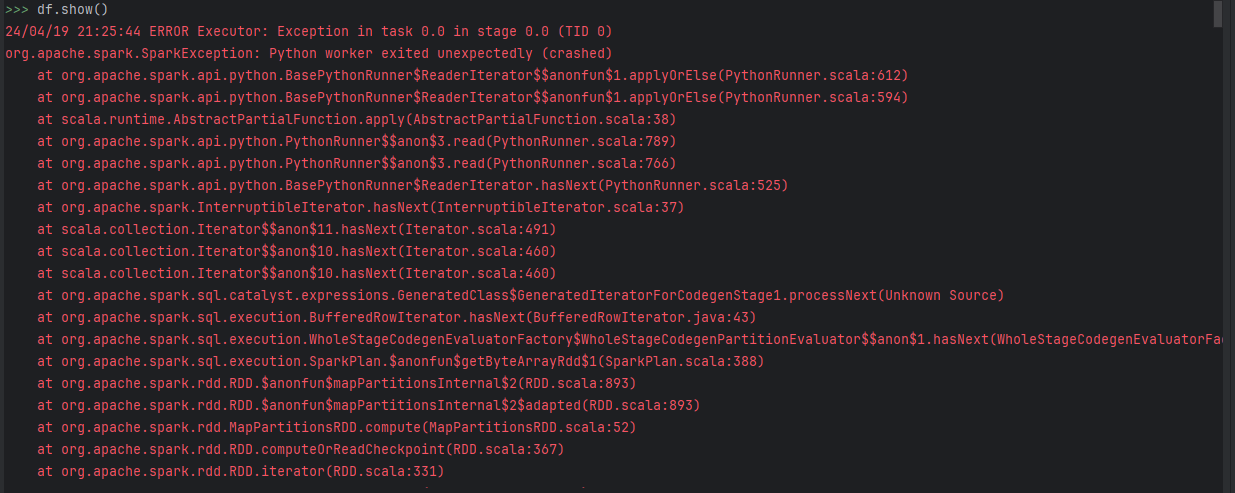
Primeiro temos um aviso sobre o Spark não carregar a biblioteca nativa do Hadoop, como consequência de não ter instalado o Hadopp ou as configurações de ambientes não estão configuradas.
Como sugestão, recomendo instalar o Spark e Hadoop novamente. Na transcrição da aula
Utilizando Spark no Windows está o passo a passo para realizar a instalação.
Quanto ao erro ao visualizar o df é por falha na execução da tarefa anterior. O interessante é que você também tenha baixado o Python na versão mais atual.
E Frederico, recomendo fortemente que para acompanhar o curso utilize o Google Colab inicialmente. Por lá não é necessário instalar Spark, configurar variáveis de ambiente e tudo mais. Você pode acompanhar nessa aula caso opte por dar continuidade com ele.
Espero ter ajudado. Qualquer dúvida, conte conosco.
Bons estudos!