Eu baixei o pacote no próprio repositório do Github do Tesseract, para a língua portuguesa.

E coloquei no diretório do tessdata:
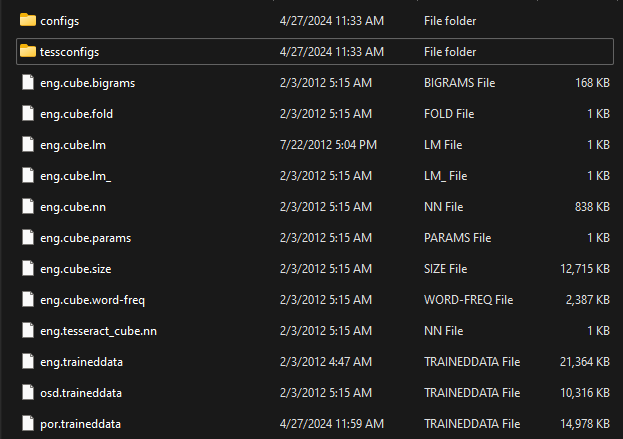
Mas essa lang não funciona por nada.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Eu baixei o pacote no próprio repositório do Github do Tesseract, para a língua portuguesa.
E coloquei no diretório do tessdata:
Mas essa lang não funciona por nada.

Rapaziada, o sufoco foi grande, mas fiz vários ajustes até que deu certo, venham comigo nessa jornada.
Primeiro, eu desinstalei o Tesseract, que estava na versão 3.02
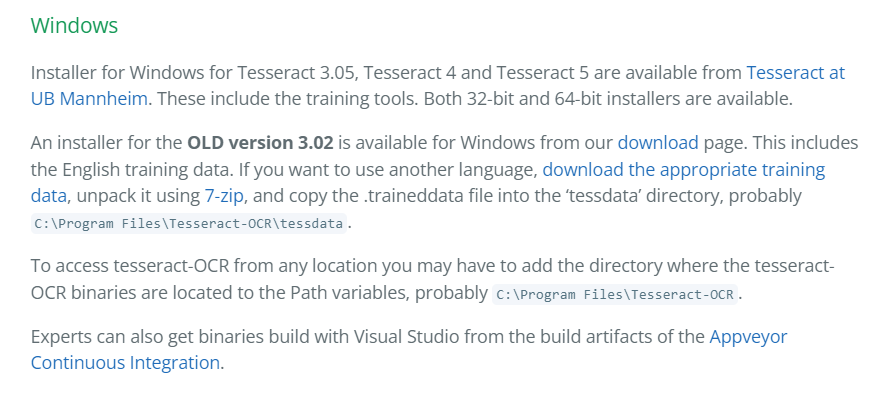
Fui no UB, que é um site oficial deles para baixar os novos Tesseract: https://github.com/UB-Mannheim/tesseract/wiki
Quando eu estava instalando, eu vi a caixinha lá de idiomas e já adicionei o por (Português).
E o código não funcionou.
Até que eu fiz vários ajustes, e deu tudo certo, segue o código novo:
import cv2
import pytesseract
# Caminho do executável do Tesseract OCR no seu sistema
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# Carrega a imagem do disco
imagem_caminho = 'imagens/trecho_livro.png'
imagem = cv2.imread(imagem_caminho)
# Converte a imagem para escala de cinza
imagem_cinza = cv2.cvtColor(imagem, cv2.COLOR_BGR2GRAY)
# Este comando exibe a imagem em uma janela
cv2.imshow('Imagem', imagem_cinza)
cv2.waitKey(0) # Espera por uma tecla ser pressionada
cv2.destroyAllWindows() # Fecha todas as janelas abertas
# Configurações para o Tesseract
config_tesseract = r'--tessdata-dir "C:\Program Files\Tesseract-OCR\tessdata" --psm 6'
# Uso da função image_to_string para extrair texto da imagem
texto = pytesseract.image_to_string(imagem_cinza, lang='por', config=config_tesseract)
# Imprime o texto extraído
print(texto)