
Ao rodar o código sugerido ao final da aula, apresenta o seguinte erro:
Carregando o arquivo data_by_year.csv utilizando o Spark
df_data_year = spark.read.format('csv') \
.option("inferSchema", 'True') \
.option("header", 'True') \
.option("sep", ',') \
.load("dbfs:/FileStore/dados/data_by_year.csv")
Convertendo o DataFrame do Spark para um DataFrame do Pandas
df_data_year = df_data_year.toPandas()
Convertendo as colunas selecionadas do DataFrame de string para float
df_data_year[['acousticness', 'danceability', 'duration_ms', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence', 'popularity']] = df_data_year[['acousticness', 'danceability', 'duration_ms', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'valence', 'popularity']].astype(float)
Salvando o DataFrame em formato Parquet no diretório especificado
path = "dbfs:/FileStore/dados_tratados/data_year.parquet"
df_data_year.to_parquet(path)
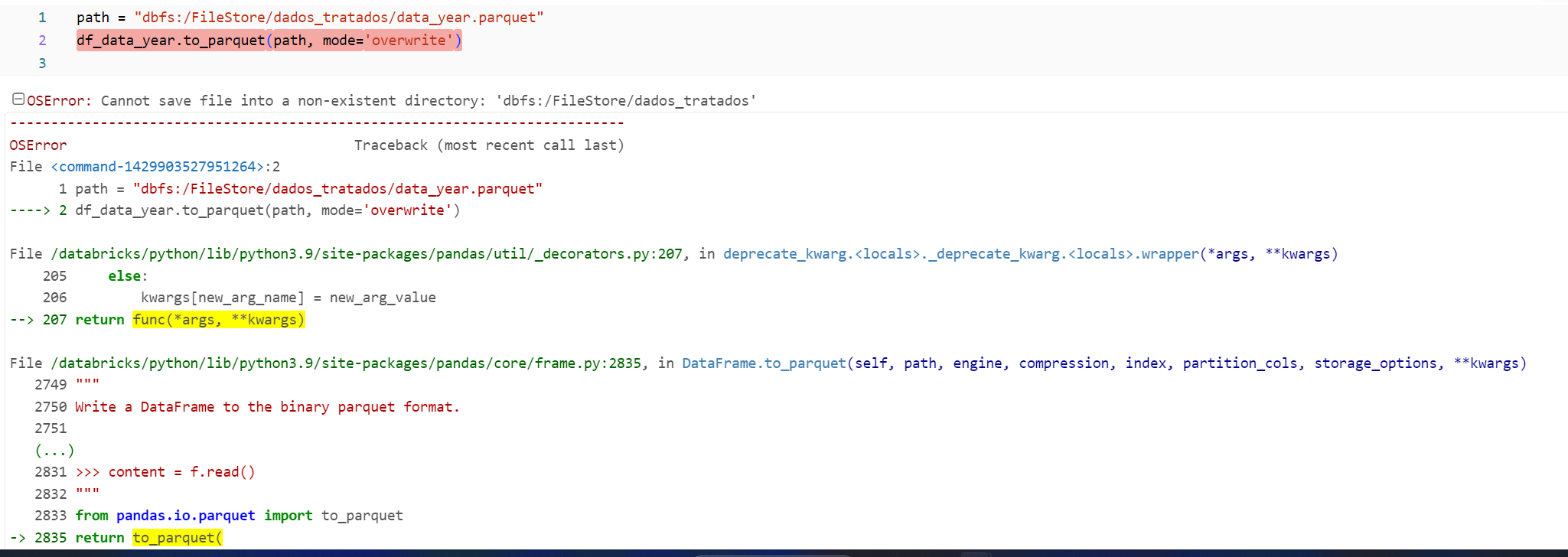 o diretório existe, pois tenho o arquivo anterior salvo lá:
o diretório existe, pois tenho o arquivo anterior salvo lá:
 Poderiam ajudar?
Poderiam ajudar?

