
Olá,
Recentemente concluí o curso de Web Scraping aqui na Alura e uso do BeautifulSoup. Já fiz scraping de alguns sites, mas esbarrei em uma limitação do BeautifulSoup. Acontece que um dos sites em que quero coletar dados é: https://www.trueachievements.com/games.aspx. A url das páginas não mudam quando selecionadas. Daí, pelo que pesquisei, uma solução é usar a biblioteca Selenium para automatizar a passagem das páginas e aí coletar os dados de cada página. Segue o meu código:
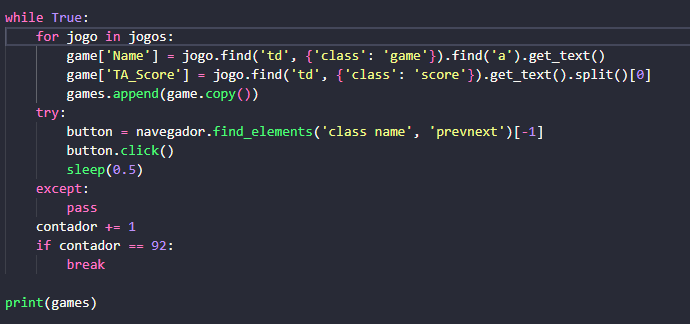
Acontece que eu coleto apenas os dados da primeira página, mesmo que o Selenium avance na paginação. Além disso, por mais que as páginas avancem, por algum motivo, nunca consigo chegar até o final, pois o processo é interrompido. Se alguém puder me ajudar de alguma forma, ou até mesmo indicar um curso aqui na plataforma, ficaria muito agradecido.
