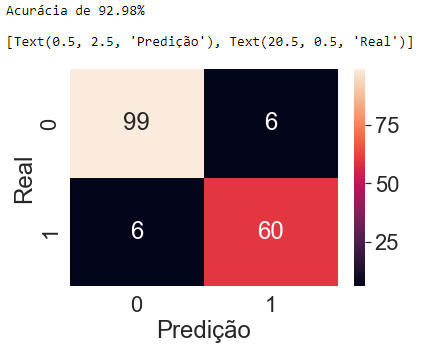
Bom dia, pessoal! Estive seguindo as instruções do professor, mas terminei ficando com uma acurácia maior que a demonstrada no vídeo. Alguém saberia dizer o que poderia estar ocasionando isso?
Muito obrigado pela atenção!
Meu código
treinoX, testeX, treinoY, testeY = train_test_split(exames.drop(columns=['id', 'diagnostico', 'exame_4', 'exame_24', 'exame_29', 'exame_33']), exames['diagnostico'], test_size=0.3)
modeloRF = RandomForestClassifier(n_estimators=100, random_state=1234)
modeloRF.fit(treinoX, treinoY)
selecionarRFE = RFE(estimator=modeloRF, n_features_to_select=5, step=1)
selecionarRFE.fit(treinoX, treinoY)
treinoRFE = selecionarRFE.transform(treinoX)
testeRFE = selecionarRFE.transform(testeX)
modeloRF = RandomForestClassifier(n_estimators=100, random_state=1234)
modeloRF.fit(treinoRFE, treinoY)
print("Acurácia de %.2f%%" % (modeloRF.score(testeRFE, testeY) * 100))
matrizConfusao = confusion_matrix(testeY, modeloRF.predict(testeRFE))
sns.set(font_scale=2)
sns.heatmap(matrizConfusao, annot=True, fmt='d').set(xlabel='Predição', ylabel='Real')Meu output