Alguém pode me ajudar, por favor!!!
Este é meu primeiro web scraping, pra falar a verdade meu primeiro projeto em programação.
Este é o repositório: https://github.com/leandromartins36/acoes_nv
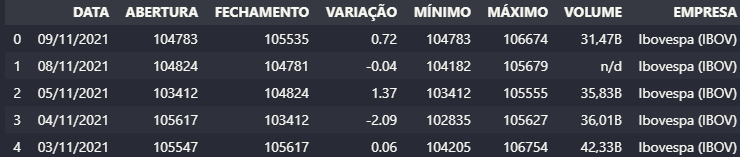
Preciso que os dados sejam exibidos como na imagem abaixo: porém são 6 empresas, e não consigui fazer o append das demais no dataframe do pandas. Utilizo o jupyter notebook.
Estão sendo lidas de um Arquivo Excel.
Empresas 0 ibovespa 1 caixa-seguridade-cxse3 2 bb-seguridade-bbse3 3 fundo-imobiliario-cxco11 4 porto-seguro-pssa3 5 sulamerica-sula11
import pandas as pd
import requests as rs
from bs4 import BeautifulSoup as bs
import ssl
from selenium import webdriver
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
import time
import pandas_datareader.data as web
#####################################
navegador = webdriver.FirefoxProfile()
navegador.set_preference("browser.privatebrowsing.autostart", True)
firefox_options = Options()
firefox_options.add_argument("--headless")
navegador = webdriver.Firefox(
firefox_profile=navegador, options=firefox_options)
agente = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
headers = {'User-Agent': agente}
#####################################
# percorre a requisição e captura o html de cada pagina
# dataframe vindo da planilha de empresas.
empresas_df = pd.read_excel('EmpresasInfomoney.xlsx')
url = "https://www.infomoney.com.br/cotacoes/"
tabelaResul = pd.DataFrame()
sigla_html = pd.DataFrame()
contador = 0
while (contador < len(empresas_df)):
for empresa in empresas_df["Empresas"]:
url_nv = ''.join([url, empresa, '/historico/'])
# print(empresa)
navegador.get(url_nv)
time.sleep(5)
conteudo = rs.get(url_nv, headers=headers)
time.sleep(3)
# encontra o elemento da pagina e grava na memoria os dados da tabela.
tb_din = navegador.find_element_by_xpath(
'//*[@id="quotes_history"]').get_attribute('outerHTML')
sigla_html = navegador.find_element_by_xpath(
'/html/body/div[4]/div/div[1]/div[1]/div/div[1]/h1')
# , index_col="DATA" incluir após thousands para colocar a data como indice.
pd_html = pd.read_html(tb_din, decimal=',', thousands='.')
df = pd.DataFrame(pd_html[0])
df['EMPRESA'] = sigla_html.text
time.sleep(3)
tabelaResul.append(df)
contador += 1
time.sleep(3)