Durante as aulas, consegui entender o que são as funções Unstack e Stack e como elas funcionam, porém faltou algo.
O 'por quê' de seus usos, ainda não ficou claro para mim, então para quais motivos usarei estas funções?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Durante as aulas, consegui entender o que são as funções Unstack e Stack e como elas funcionam, porém faltou algo.
O 'por quê' de seus usos, ainda não ficou claro para mim, então para quais motivos usarei estas funções?


Olá, Igor, tudo bem?
Os métodos stack() e unstack() são utilizados para remodelar as tabelas que passam pelo métodos de pivot ou que já estão pivotadas em torno de uma ou mais colunas sendo elas Séries ou DataFrames. Eles são adequados quando trabalhamos com dados Multi-indexados, ou seja, dados com arranjos de index que possuem 2 ou mais níveis com uma hierarquia entre eles.
Logo abaixo, trazemos exemplos de utilização dos métodos stack() e unstack() seguindo a documentação sobre técnicas de reshaping e pivot do pandas (https://pandas.pydata.org/docs/user_guide/reshaping.html).
O método stack() realiza um "pivot" de uma coluna que pode estar relacionada com o index/multindex já existente, retornando um DataFrame em que esta coluna é transformada em um index com suas linhas no nível mais interno do Multindex dos dados.
Para facilitar a visualização, seguindo o exemplo em que temos um DataFrame (df2), se aplicarmos o método stack() as colunas A e B serão "pivotadas" e relacionadas com o Multindex (first e second). Assim, o novo index gerado pelo método será o terceiro nível do Multindex do nosso DataFrame, com os dados posicionados de acordo com a relação entre eles.
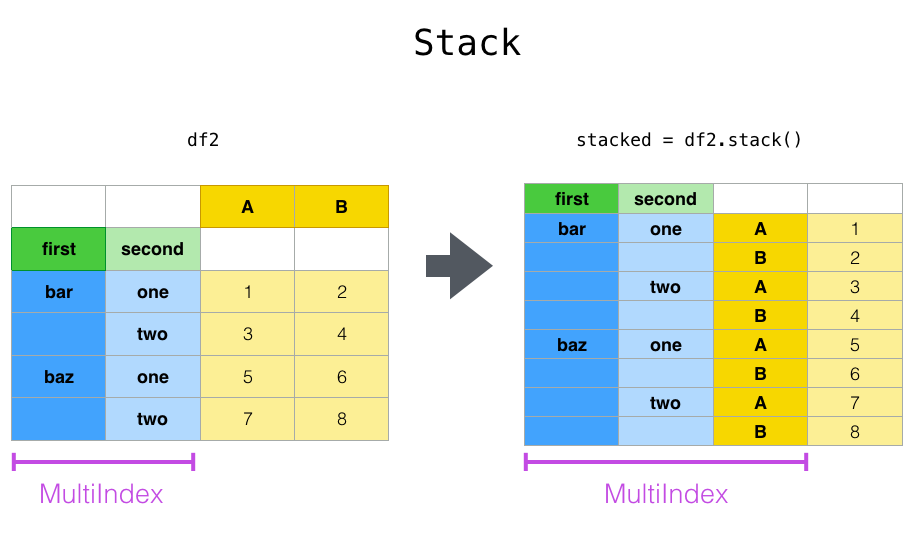
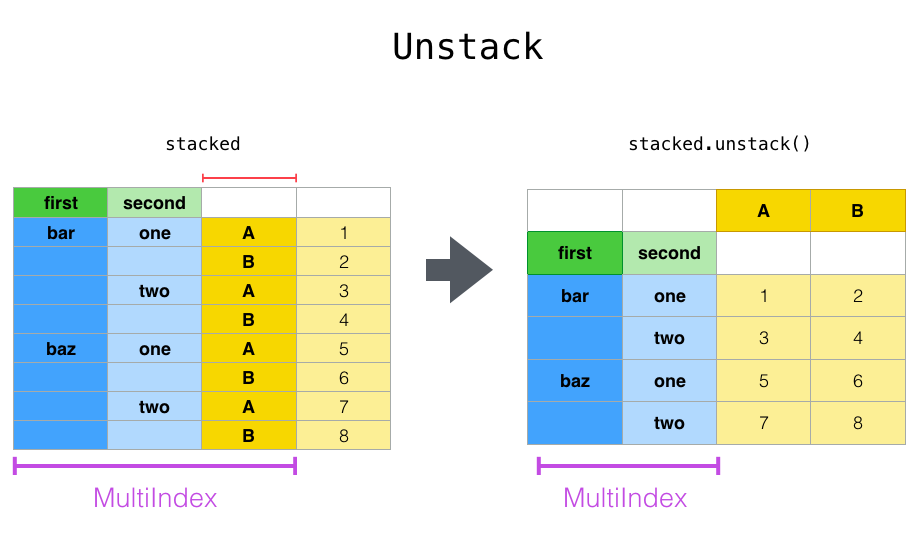
Já o método unstack() realiza o contrário do stack(), ou seja, faz o "pivot" de um dado index do nosso Multindex para as colunas, retornando um DataFrame em que estes dados "pivotados" são divididos em colunas que estão relacionadas com nosso o Multindex dos dados.
Para facilitar a visualização, seguindo o exemplo em que temos o nosso DataFrame após a ação do método stack() (stacked), se aplicarmos o método unstack() , por padrão, o último nível do Multindex (terceiro nível) é passado para as colunas e assim as colunas A e B voltam ao estado original (df2 ou stacked.unstack()).
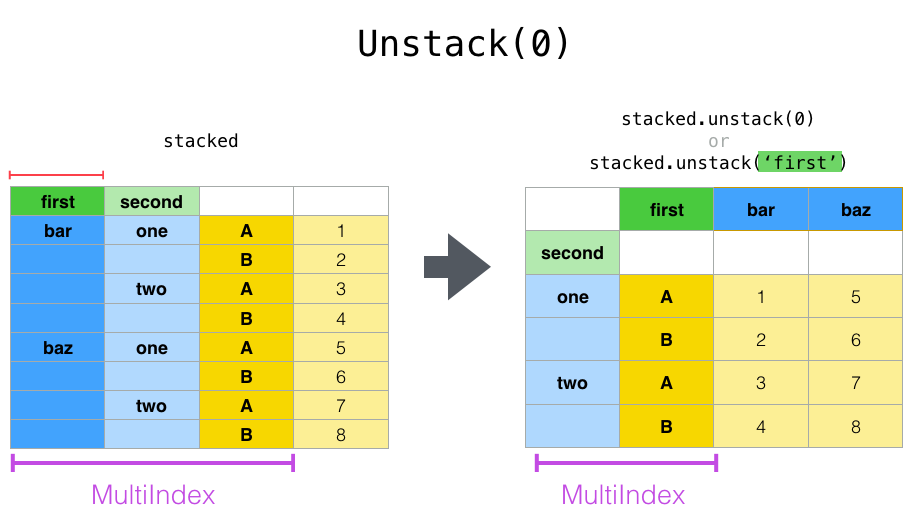
Caso quisermos utilizar o método unstack() para transformar outros níveis de index para colunas, basta colocar o nível que desejamos fazer a ação lembrando que o index é numerado de 0** até **n-1, ou seja, se quisermos por exemplo usar o unstack no primeiro nível usamos (unstack(0)) e no segundo nível (unstack(1)).
Esperamos que tenhamos ajudado a entender mais sobre esses métodos e qualquer dúvida é só chamar!
Abraços e bons estudos!
Opa, muito obrigado, Afonso!