
Estou aprendendo machine learning com o dataset iris. Tentei encontrar o valor de K ideal de 2 formas diferentes: em uma o valor de k ideal foi 5 e no outro k=14 e não consigo entender a divergência. Segue o que eu fiz:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn import metrics
import matplotlib.pyplot as plt
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=11, test_size=0.20)
#metodo1
k_range = range(1, 30)
scores = {}
scores_list = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k) #Creating the Model
knn.fit(X=X_train, y=y_train) #Training the Model
y_pred = knn.predict(X_test)
scores[k] = metrics.accuracy_score(y_test, y_pred)
scores_list.append(metrics.accuracy_score(y_test, y_pred))
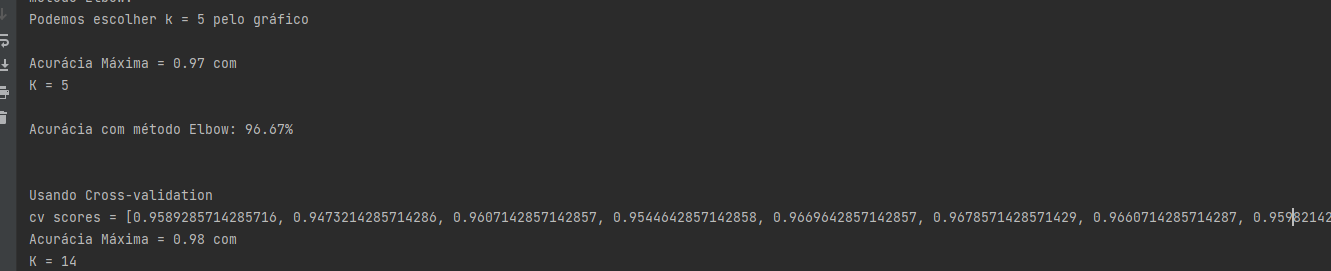
print(f'Acurácia Máxima = {max(scores_list):.2f} com \nK = {scores_list.index(max(scores_list)) + 1}')
#Atenção: k não começa em zero mas o indice da lista sim!
#aqui o valor encontrado de k foi k =5 com Acurácia Máxima de 0.97
#metodo2
neighbors = range(1, 30)
cv_scores = []
n_splits = 20
kfold = KFold(n_splits=n_splits, shuffle=True)#random_state=11
for k in neighbors:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(estimator=knn, X=iris.data, y=iris.target, cv=kfold,
scoring='accuracy') # X-train y_train
cv_scores.append(scores.mean())
print(f'cv scores = {cv_scores}')
cv_scores = [round(valor, 2) for valor in cv_scores]
acc_max = round(max(cv_scores), 2)
print(f'Acurácia Máxima = {acc_max:.2f} com \nK = {cv_scores.index(acc_max) + 1}')
##aqui o valor encontrado de k foi k =14 com Acurácia Máxima de 0.98 código no ideone: https://ideone.com/vIHbf1
Resultados:
Gostaria de entender por que os valores de k encontrados foram diferentes.
