Embora o uso de VARCHAR para IDs (como chaves primárias) funcione e ofereça flexibilidade, ele deve ser evitado em favor de tipos numéricos (inteiros, bigints) ou UUIDs otimizados, principalmente devido a impactos no desempenho e no armazenamento.
Aqui estão os principais motivos para evitar VARCHAR em IDs:
Performance de Indexação e Busca
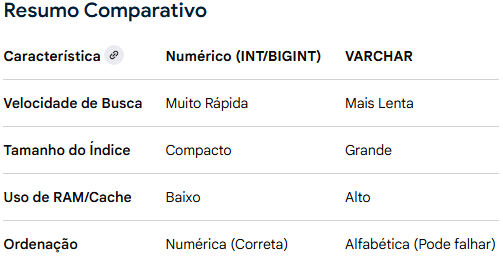
Comparação lenta: Comparar números (inteiros) é muito mais rápido para o processador do que comparar strings, que precisam ser analisadas caractere por caractere (respeitando regras de collation ou acentuação).
Índices maiores: VARCHAR ocupa mais espaço em disco e na memória (cache). Índices grandes significam que menos dados cabem na memória RAM, resultando em mais leituras de disco e consultas mais lentas.
Fragmentação: Índices baseados em texto (especialmente se não forem sequenciais) tendem a causar mais fragmentação no banco de dados com o tempo.
Uso de Armazenamento
1- Sobrecarga (overhead): VARCHAR precisa de 1 ou 2 bytes extras para armazenar o comprimento da string, além dos caracteres em si.
2- Espaço desnecessário: Se o tamanho do VARCHAR for definido como alto (ex: VARCHAR(255)), pode haver desperdício, embora o VARCHAR economize espaço em comparação ao CHAR por armazenar apenas o necessário, ele ainda perde para um INT ou BIGINT que ocupam espaço fixo e compacto (4 ou 8 bytes).
- Integridade e Tipo de Dado
Ordenação incorreta: Strings são ordenadas alfabeticamente, não numericamente. 10 pode vir antes de 2 em uma ordenação VARCHAR, o que quebra a lógica de IDs sequenciais.
Uso inadequado: IDs devem ser identificadores únicos e estáveis. VARCHAR permite qualquer caractere, o que pode levar a inconsistências, espaços em branco acidentais ('123 ' vs '123') e dificuldades na validação.
Quando o VARCHAR é aceitável?
O uso de VARCHAR é aceitável quando o ID é naturalmente alfanumérico e de tamanho fixo, como códigos de aeroportos (IATA) ou códigos postais, mas mesmo nesses casos, CHAR costuma ser mais performático que VARCHAR.