
# Comparação de Modelos de Classificação para inadimplência
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, ConfusionMatrixDisplay
)
import matplotlib.pyplot as plt
# 1. Carregar dados
df = pd.read_csv('emp_automovel.csv')
# Sanity checks iniciais
df_cols = df.columns.tolist()
assert 'inadimplente' in df_cols, "Coluna 'inadimplente' ausente no DataFrame!"
assert not df.empty, "DataFrame carregado está vazio!"
print("DADOS CARREGADOS:")
print(f"Shape: {df.shape}")
print(f"Distribuição da variável target:")
print(df['inadimplente'].value_counts())
print(f"Taxa de inadimplência: {df['inadimplente'].mean():.2%}")
print()
# 2. Preparar variáveis
X = df.drop(columns=['inadimplente'])
y = df['inadimplente']
# 3. Divisão treino, validação e teste
X_train_val, X_test, y_train_val, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
X_train, X_val, y_train, y_val = train_test_split(
X_train_val, y_train_val, test_size=0.25, stratify=y_train_val, random_state=42
)
print("DIVISÃO DOS DADOS:")
print(f"Treino: {X_train.shape[0]} amostras")
print(f"Validação: {X_val.shape[0]} amostras")
print(f"Teste: {X_test.shape[0]} amostras")
print()
# 4. Definição dos modelos
modelos = {
'Árvore de Decisão': DecisionTreeClassifier(max_depth=5, random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42),
'Random Forest Balanceado': RandomForestClassifier(
n_estimators=100, max_depth=5, class_weight='balanced', random_state=42
)
}
# 5. Treino, predição e cálculo de métricas
print("TREINANDO MODELOS...")
resultados = []
for nome, modelo in modelos.items():
modelo.fit(X_train, y_train)
y_pred = modelo.predict(X_val)
acc = accuracy_score(y_val, y_pred)
prec = precision_score(y_val, y_pred, zero_division=0)
rec = recall_score(y_val, y_pred)
f1 = f1_score(y_val, y_pred)
cm = confusion_matrix(y_val, y_pred)
resultados.append({
'Modelo': nome,
'Acurácia': acc,
'Precisão': prec,
'Recall': rec,
'F1-Score': f1,
'ConfusionMatrix': cm
})
# 6. Exibir resultados resumidos
df_res = pd.DataFrame(resultados).drop(columns=['ConfusionMatrix'])
print("=== MÉTRICAS DE DESEMPENHO NA VALIDAÇÃO ===")
print()
for _, row in df_res.iterrows():
print(f"{row['Modelo']}:")
print(f" Acurácia: {row['Acurácia']:.2%}")
print(f" Precisão: {row['Precisão']:.2%}")
print(f" Recall: {row['Recall']:.2%}")
print(f" F1-Score: {row['F1-Score']:.2%}")
print()
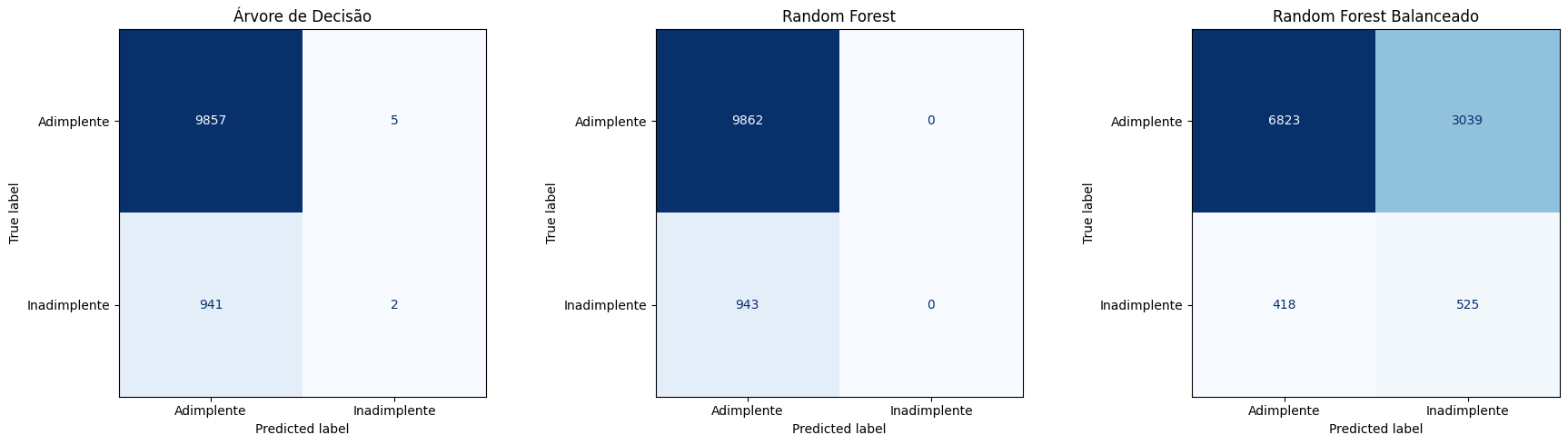
# 7. Plot das matrizes de confusão
fig, axes = plt.subplots(1, len(modelos), figsize=(18, 5))
for ax, res in zip(axes, resultados):
disp = ConfusionMatrixDisplay(
confusion_matrix=res['ConfusionMatrix'],
display_labels=['Adimplente', 'Inadimplente']
)
disp.plot(ax=ax, cmap='Blues', colorbar=False)
ax.set_title(res['Modelo'])
plt.tight_layout()
plt.show()
# Análise detalhada das matrizes
print("ANÁLISE DETALHADA DAS MATRIZES DE CONFUSÃO:")
print()
for res in resultados:
cm = res['ConfusionMatrix']
nome = res['Modelo']
print(f"{nome}:")
print(f" Verdadeiros Negativos (TN): {cm[0,0]}")
print(f" Falsos Positivos (FP): {cm[0,1]}")
print(f" Falsos Negativos (FN): {cm[1,0]}")
print(f" Verdadeiros Positivos (TP): {cm[1,1]}")
print(f" Inadimplentes detectados: {cm[1,1]} de {cm[1,0] + cm[1,1]}")
print(f" Taxa de detecção: {cm[1,1]/(cm[1,0] + cm[1,1]):.2%}")
print()
# 8. Interpretação final
print("INTERPRETAÇÃO FINAL:")
print()
melhor_recall = max(resultados, key=lambda x: x['Recall'])
melhor_f1 = max(resultados, key=lambda x: x['F1-Score'])
melhor_acc = max(resultados, key=lambda x: x['Acurácia'])
print(f"Melhor Recall (detecção de inadimplentes): {melhor_recall['Modelo']} ({melhor_recall['Recall']:.2%})")
print(f"Melhor F1-Score (equilíbrio): {melhor_f1['Modelo']} ({melhor_f1['F1-Score']:.2%})")
print(f"Melhor Acurácia: {melhor_acc['Modelo']} ({melhor_acc['Acurácia']:.2%})")
print()
# Sanity checks
assert df_res['Acurácia'].between(0.0, 1.0).all(), "Alguma acurácia está fora do intervalo válido [0,1]!"
print("Todos os sanity checks passaram!")

