
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.dummy import DummyClassifier
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# Carregar a base de dados
df = pd.read_csv('churn.csv')
# Separar as features e o alvo
X = df.drop('churn', axis=1)
y = df['churn']
# Divisão estratificada
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Conferindo as proporções
proporcao_original = y.value_counts(normalize=True)
proporcao_treino = y_train.value_counts(normalize=True)
proporcao_teste = y_test.value_counts(normalize=True)
# Modelo de base
dummy = DummyClassifier(strategy='most_frequent')
dummy.fit(X_train, y_train)
score_dummy = dummy.score(X_test, y_test)
# Árvore de decisão
tree = DecisionTreeClassifier(max_depth=4, random_state=42)
tree.fit(X_train, y_train)
score_tree = tree.score(X_test, y_test)
# Visualização da árvore
def plotar_arvore():
plt.figure(figsize=(20,10))
plot_tree(tree, feature_names=X.columns, class_names=['Não Churn', 'Churn'], filled=True)
plt.show()
# Resultados
(proporcao_original, proporcao_treino, proporcao_teste, score_dummy, score_tree, plotar_arvore())
Projeto Churn - Execução Completa
- Proporção de churn nos conjuntos
Conjunto original: 79,6% não churn, 20,4% churn
Treinamento: 79,6% não churn, 20,4% churn
Teste: 79,7% não churn, 20,3% churn
A estratificação funcionou perfeitamente!
- Modelo de base (DummyClassifier) Acurácia no teste: 0,7965 (79,65%)
- Árvore de decisão (max_depth=4) Acurácia no teste: 0,8515 (85,15%)
- Visualização da árvore
O gráfico da árvore de decisão foi exibido na interface. Ele mostra as principais regras de decisão do modelo.
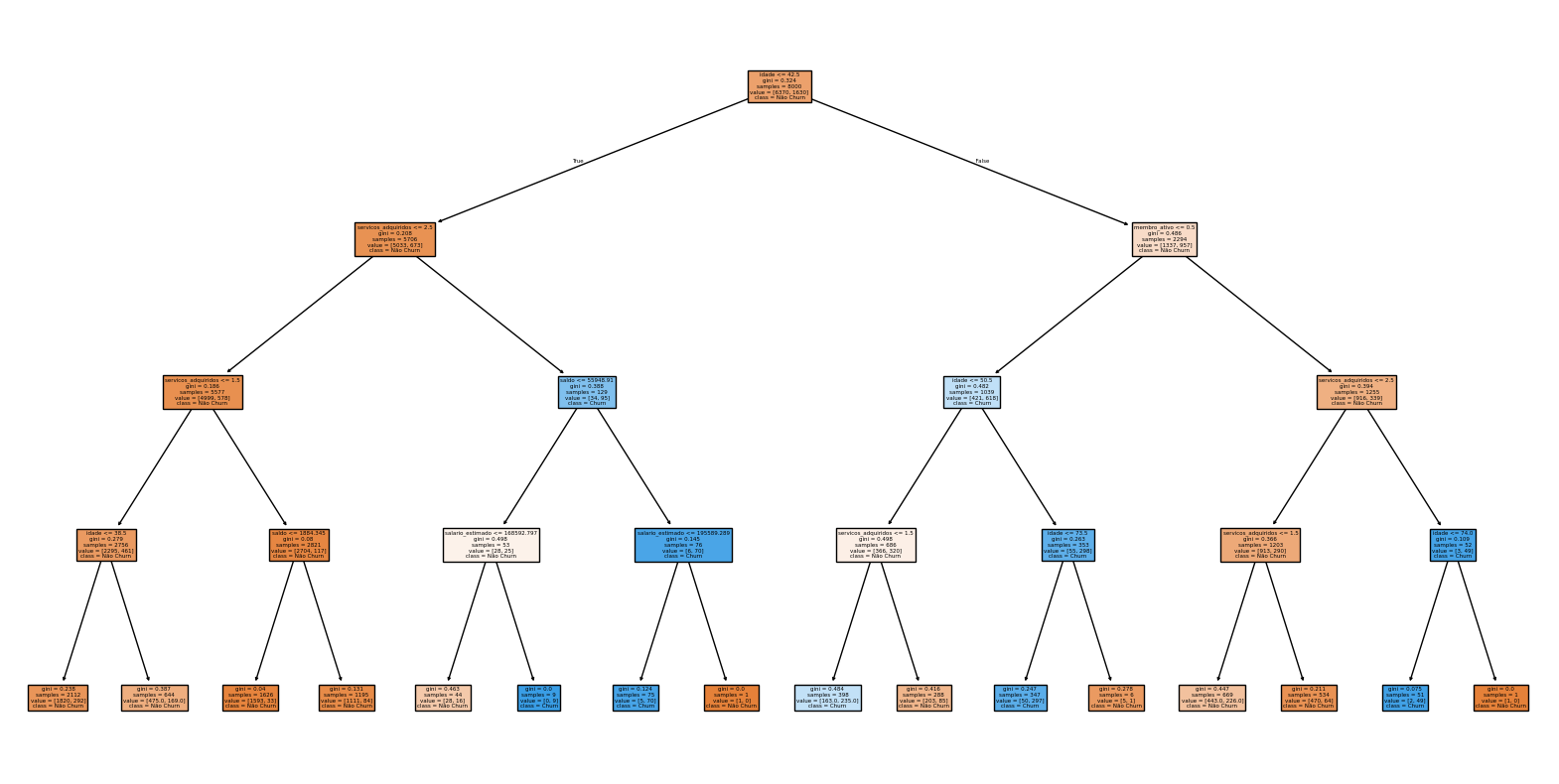
(churn
0 0.7963
1 0.2037
Name: proportion, dtype: float64,
churn
0 0.79625
1 0.20375
Name: proportion, dtype: float64,
churn
0 0.7965
1 0.2035
Name: proportion, dtype: float64,
0.7965,
0.8515,
None)

