Fiquei muito feliz quando ví o novo curso "LangChain e Python" na Alura. Não poderia chegar em um momento melhor para minha trilha de aprendizagem.
O problema é que os responsáveis pelo curso optaram por utilizar o modelo de LLM da OpenAI via API e isso tem custo, quase o mesmo valor mensal da Alura. Ou seja, esse curso para ser feito seguindo os mesmos passos do professor Guilherme Silveira, é necessário um investimento adicional que creio que a maioria de nós alunos não tem condições. Pelo menos eu não tenho.
Só acho estranho terem optado por este modelo sabendo disso. Acredito que tudo foi pensado antes, e se não foi deveriam ao menos ter pensado no impacto que teria se caso um aluno (como a maioria) tivesse que usar um outro modelo open source:
- Diferente configuração
- Uso de outros parâmetros
- Importação diferente
- Métodos diferentes
Imaginem agora um aluno que não é tão avançado ter que fazer todos esses passos sem ajuda de um professor? Afinal nós estamos acostumados a ter todo o suporte e conteúdo completo nos demais cursos da Alura, e é no mínimo com muito rúido que conseguiríamos fazer tais adaptações tendo que utilizar fontes externas de consultas, quando o que queríamos era um aprendizado direto desde a configuração até a conclusão do curso.
Indico fortemente que a diretoria avalie a possibilidade de incluir um vídeo guiando nas configurações ou adaptações necessárias para alunos que pretendem utilizar os modelos OpenSource. Ou até lançar uma reformulação do curso com tal modelo.


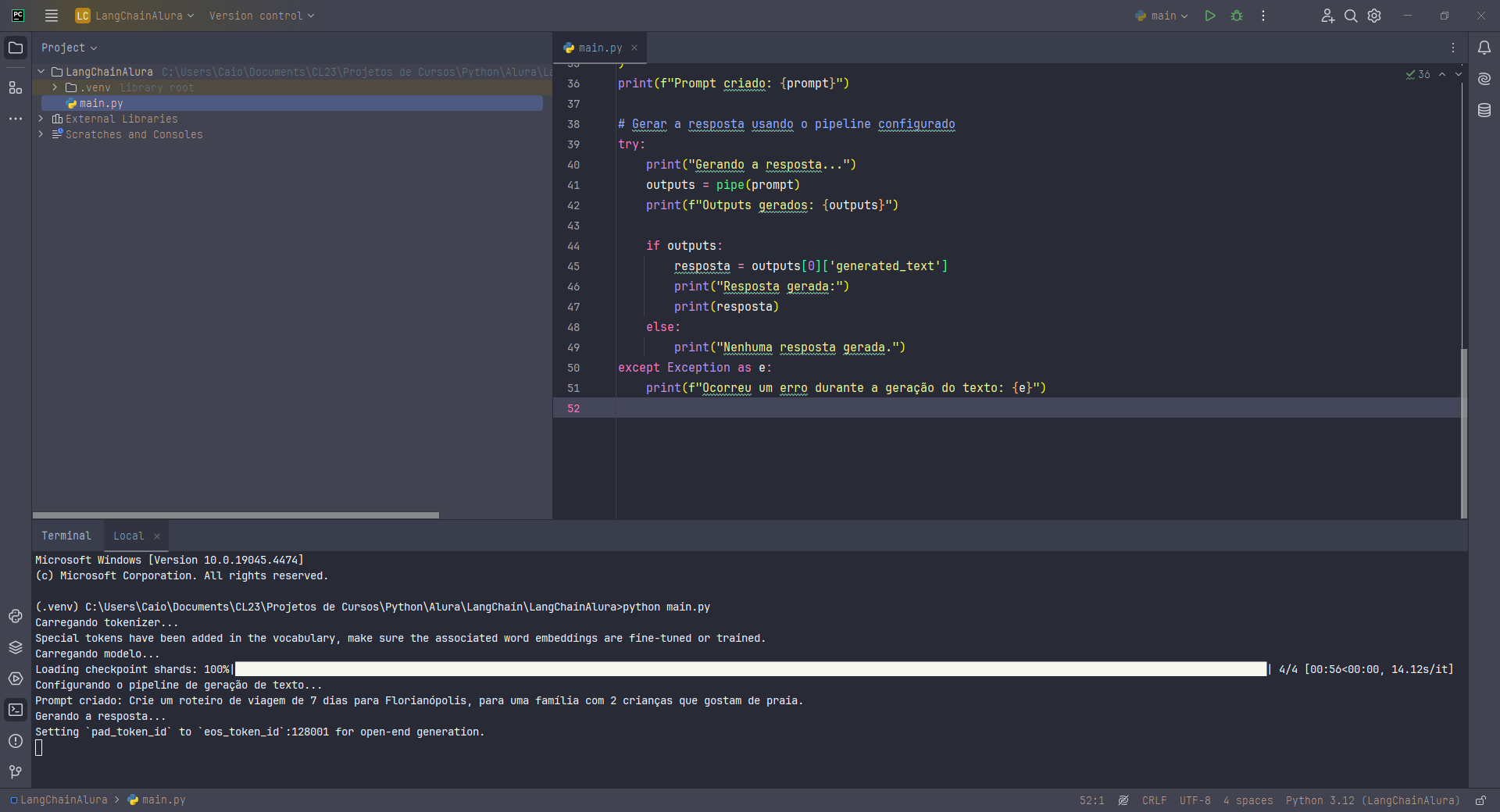
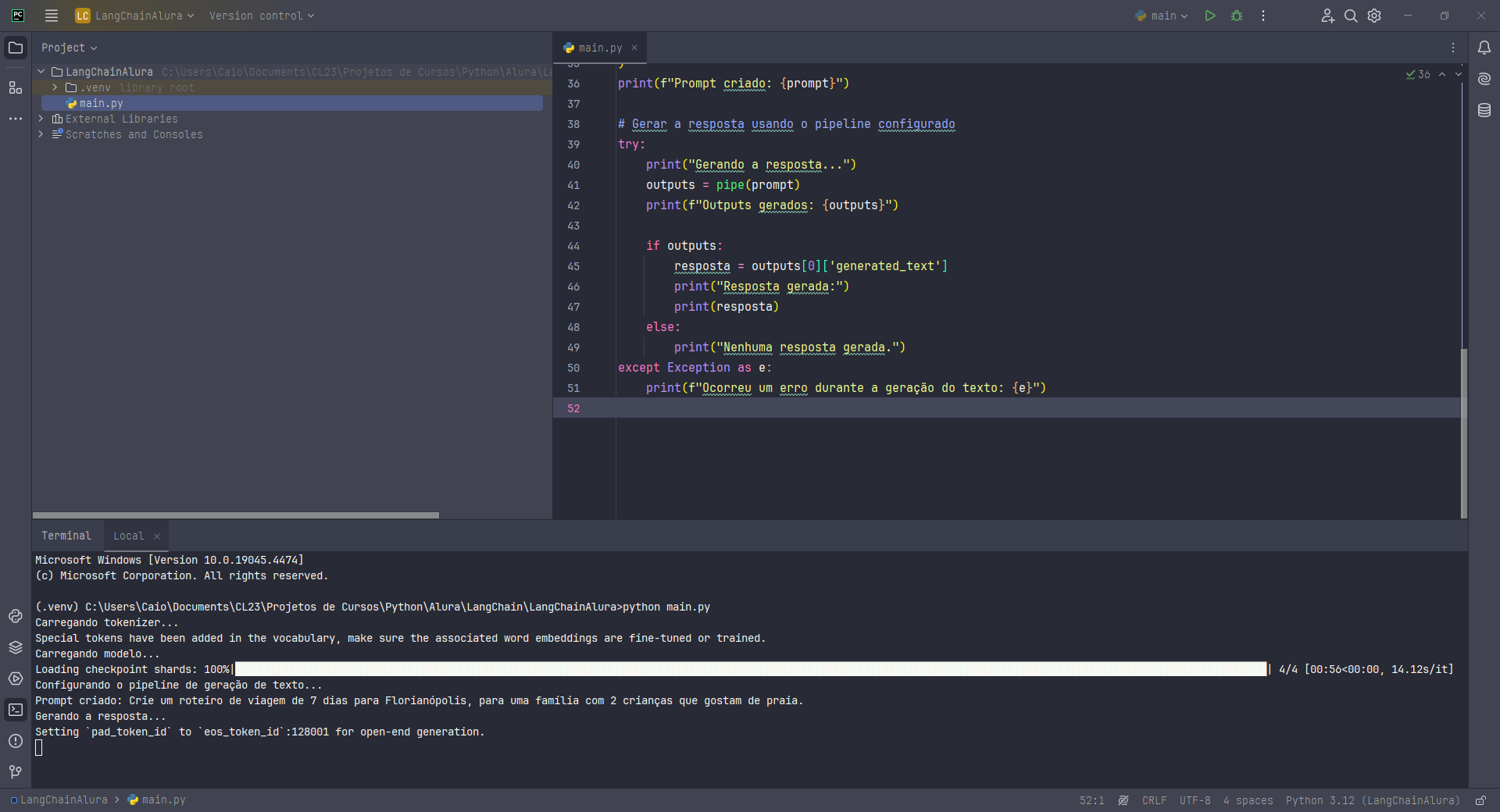 Estava tendo alguns erros e resolvi eu mesmo tentar resolver para poder chegar aqui com alguma resposta.
Estava tendo alguns erros e resolvi eu mesmo tentar resolver para poder chegar aqui com alguma resposta.