Oi Guilherme, tudo bem?
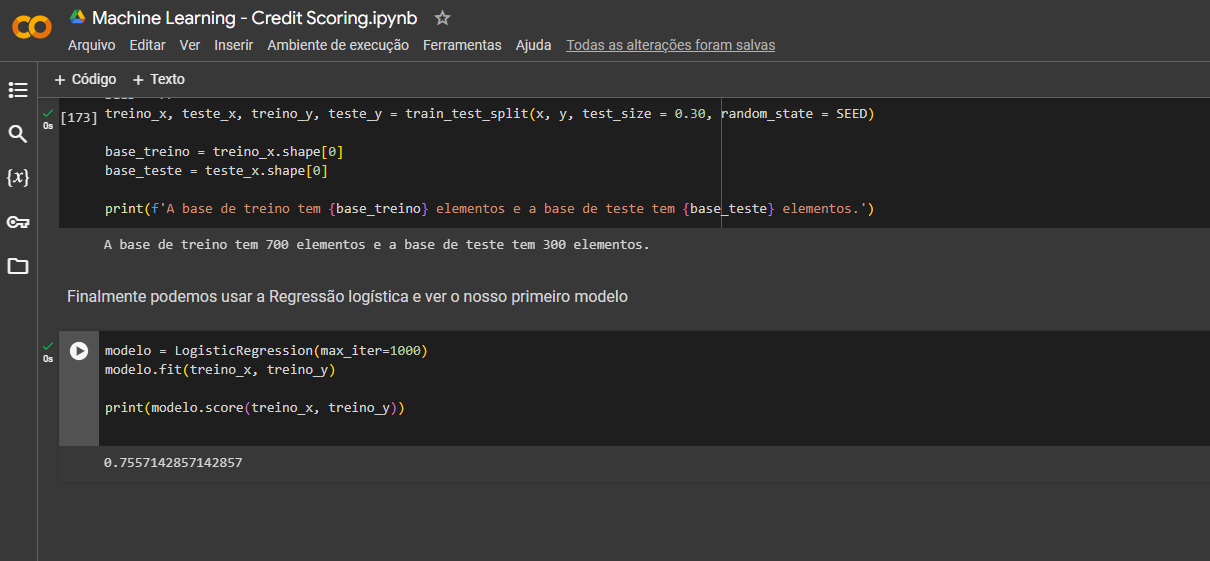
Notei que a variação é bem pequena, não se preocupe, essa pequena variação no resultado do modelo de regressão logística pode ocorrer por diversas razões e não significa necessariamente que você fez algo errado.
Algumas princiapis possibilidades dessas diferenças são:
Precisão de Ponto Flutuante: A precisão de ponto flutuante em diferentes sistemas ou ambientes de execução pode levar a pequenas diferenças nos cálculos
Divisão dos Dados: Mesmo que você tenha usado o mesmo random_state para a divisão dos dados em treino e teste, pequenas diferenças nos dados ou na forma como o train_test_split é aplicado podem levar a conjuntos diferentes, resultando em pequenas variações na acurácia.
Versão das Bibliotecas: Diferenças nas versões das bibliotecas utilizadas (como scikit-learn, pandas, numpy, etc.) podem levar a pequenas variações nos resultados.
Uma variação tão pequena 0.01, como a que você observou é normal, ela pode ser atribuída a variações aleatórias normais durante o treinamento do modelo. Portanto, não se preocupe, ela está dentro do esperado.
Espero ter esclarecido e fico à disposição.
Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!

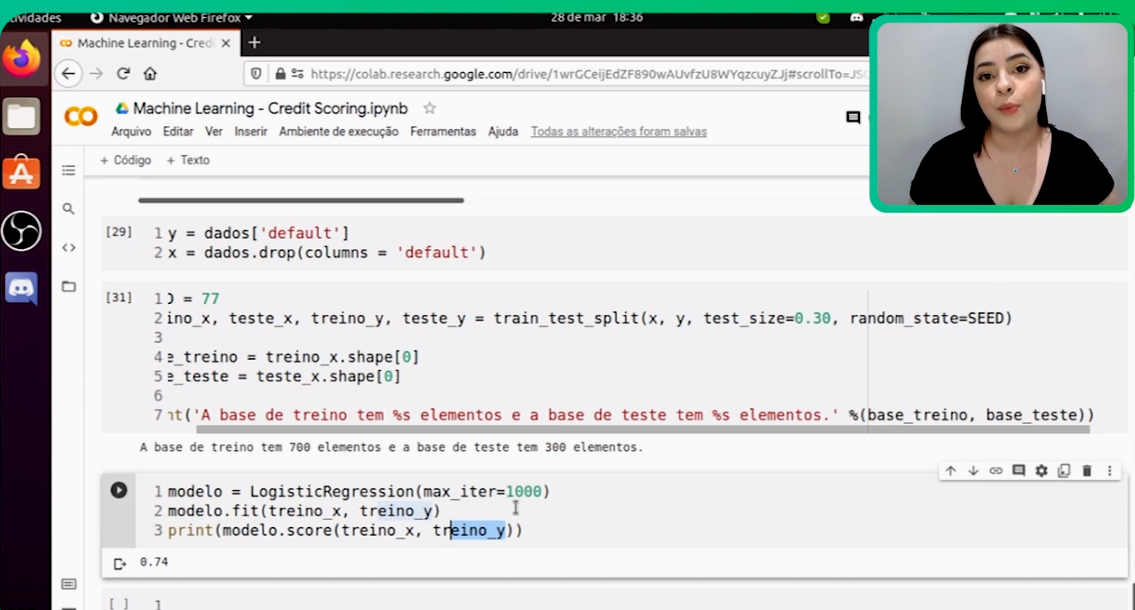 Resultado na aula foi de 0.74
Resultado na aula foi de 0.74