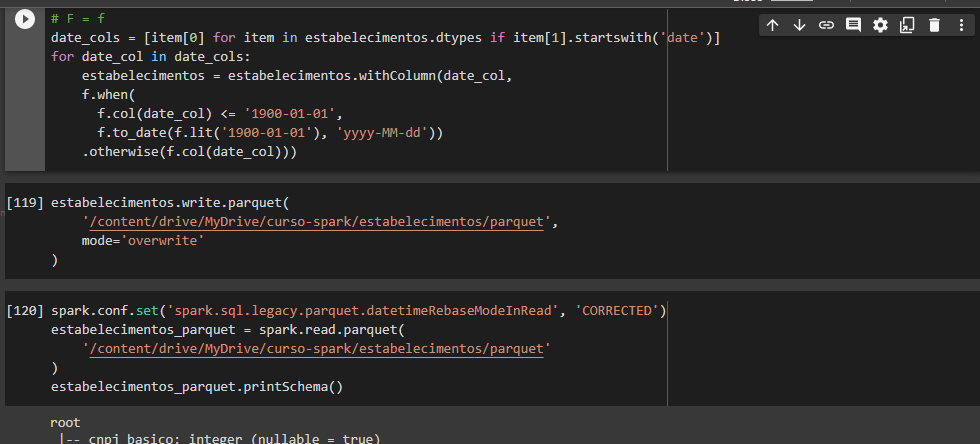
Também enfrentei o mesmo problema, segue a correção que apliquei após consultar alguns fóruns.
Ao rodar o comando abaixo diretamente, está dando erro pois há datas invalidas em algumas colunas de dados do dataframe.
estabelecimentos.write.parquet(
'/content/drive/MyDrive/curso-spark/estabelecimentos/parquet',
mode='overwrite'
)Para tratar este ponto criei uma célula que corrige as datas do dataframe, basta adicionar isso antes de realizar a escrita.
# F = f
date_cols = [item[0] for item in estabelecimentos.dtypes if item[1].startswith('date')]
for date_col in date_cols:
estabelecimentos = estabelecimentos.withColumn(date_col,
f.when(
f.col(date_col) <= '1900-01-01',
f.to_date(f.lit('1900-01-01'), 'yyyy-MM-dd'))
.otherwise(f.col(date_col)))Uma vez realizada a escrita, caso vá realizar a leitura é preciso configurar a classe de leitura do spark. Com isso o modo de compatibilidade ficará ativo e conseguirá realizar a leitura do parquet.
spark.conf.set('spark.sql.legacy.parquet.datetimeRebaseModeInRead', 'CORRECTED')Versão final do commands