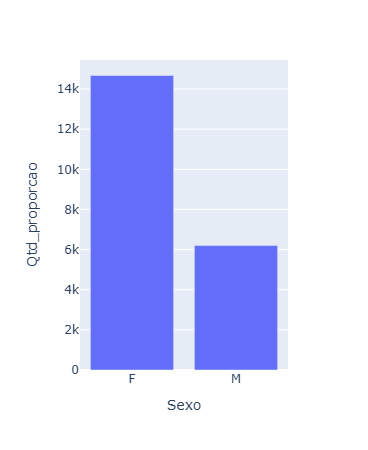
Eu realizei o desafio e queria saber se há algo que pode ser melhorado (Obs: Para fazer a consulta'query' precisei transformar o arquivo em DataFrame)
local_arquivo_desafio = '/FileStore/relatorio_inscricao_dados_abertos_fies_22021.csv'
import pyspark.pandas as ps
df_desafio = ps.read_csv(local_arquivo_desafio, index_col= 'ID do estudante', sep=';')
df_desafio = ps.DataFrame(df_desafio)
# Exclusão de valores NaN
df_desafio.dropna(inplace=True)
query_propocao = ps.sql('''
SELECT Sexo, COUNT(Sexo) AS Qtd_proporcao
FROM {DF}
GROUP BY sexo
''', DF=df_desafio)
query_propocao.plot.bar(x='Sexo', y= 'Qtd_proporcao')