A alguns dias comecei esta formação AWS Data Lake e esta sendo um transtorno ter códigos do curso desatualizados . Olhei no fórum e outra pessoa pergunta quando haverá atualização e é informada que não há previsão !
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

A alguns dias comecei esta formação AWS Data Lake e esta sendo um transtorno ter códigos do curso desatualizados . Olhei no fórum e outra pessoa pergunta quando haverá atualização e é informada que não há previsão !


Olá, Fabiana, tudo bem?
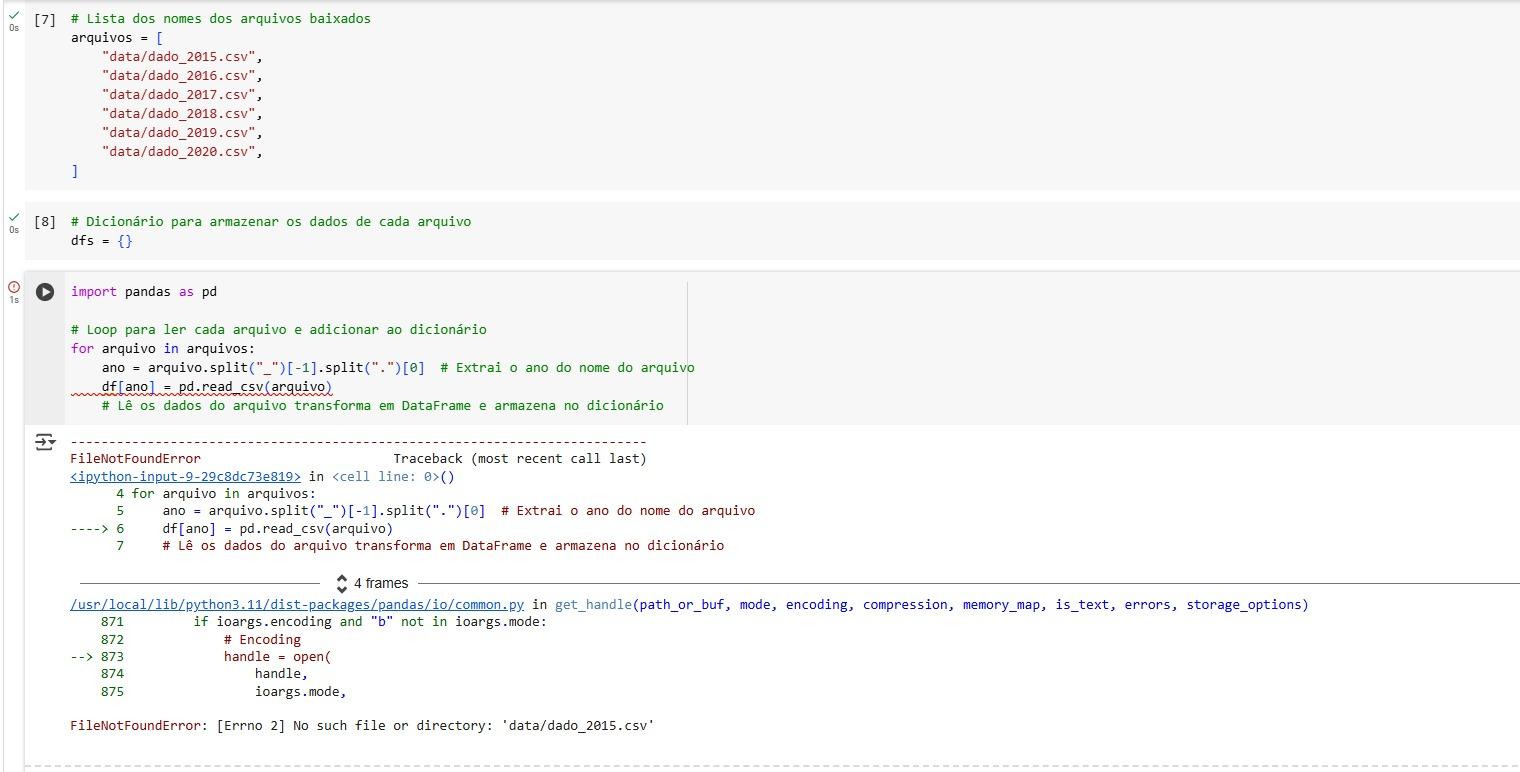
O erro FileNotFoundError: [Errno 2] No such file or directory: 'data/dados_2015.csv' aconteceu porque o código que deveria baixar os arquivos CSV da internet não conseguiu salvar nenhum arquivo localmente.O que pode ter acontecido é que o urllib.request.urlretrieve() foi bloqueado pelo servidor do site da Prefeitura de Boston, gerando o erro HTTP Error 403: Forbidden.
Alguns sites bloqueiam acessos automáticos feitos por scripts que não parecem com navegadores. A função urlretrieve do Python envia uma requisição sem identificar o "User-Agent", o que fez o servidor recusar o download. Esse bloqueio é uma forma de proteção contra robôs.
A solução que encontrei foi usar a biblioteca requests, que permite personalizar os cabeçalhos da requisição (headers). Com isso, conseguimos simular o comportamento de um navegador adicionando um User-Agent, o que permite que o download seja aceito pelo servidor. Então peço que faça o seguinte ajuste.
import urllib.request
#Módulo utilizado para fazer o download de dados de uma url
# Função para baixar dados de um URL e salvar em um arquivo
def extract_data(url, filename): #Parâmetros da função que espera 2 argumentos
try:
urllib.request.urlretrieve(url, filename)
# Baixa o arquivo do URL e salva no local especificado
except Exception as e:
print(e) # Imprime qualquer erro que ocorra durante o processo
Por:
import requests
def extract_data(url, filename):
try:
headers = {'User-Agent': 'Mozilla/5.0'} # Simula um navegador
response = requests.get(url, headers=headers)
response.raise_for_status() # Gera erro se a resposta não for 200
with open(filename, 'wb') as f:
f.write(response.content) # Salva o conteúdo no arquivo
print(f"Arquivo salvo com sucesso: {filename}")
except Exception as e:
print(f"Erro ao baixar {filename}: {e}")
extract_data recebe uma URL e o nome de um arquivo local.User-Agent).Assim, você consegue baixar os dados corretamente e evitar o erro de "arquivo não encontrado" ao tentar carregá-los com pandas.
❗ Ao inserir o código acima é necessário que você reinicie o seu notebook e depois execute as células, seguindo os passos:
No menu de ferramentas do Google Colaboratory, clicar em "Ambientes de execução";
Selecionar a opção "Reiniciar sessão e executar tudo".
Para realizar essas etapas, você pode acompanhar a imagem abaixo:

Espero ter ajudado.
Qualquer dúvida, compartilhe no fórum.
Abraços e bons estudos!