Olá, após assistir a aula extra de pandas, tentei buscar uma tabela pela url. Embora ela esteja no site, retornou um ValueError No tables found. Então, fiquei sem entender porquê a tabela não foi encontrada.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Olá, após assistir a aula extra de pandas, tentei buscar uma tabela pela url. Embora ela esteja no site, retornou um ValueError No tables found. Então, fiquei sem entender porquê a tabela não foi encontrada.


Oii Ubiratan, como você está?
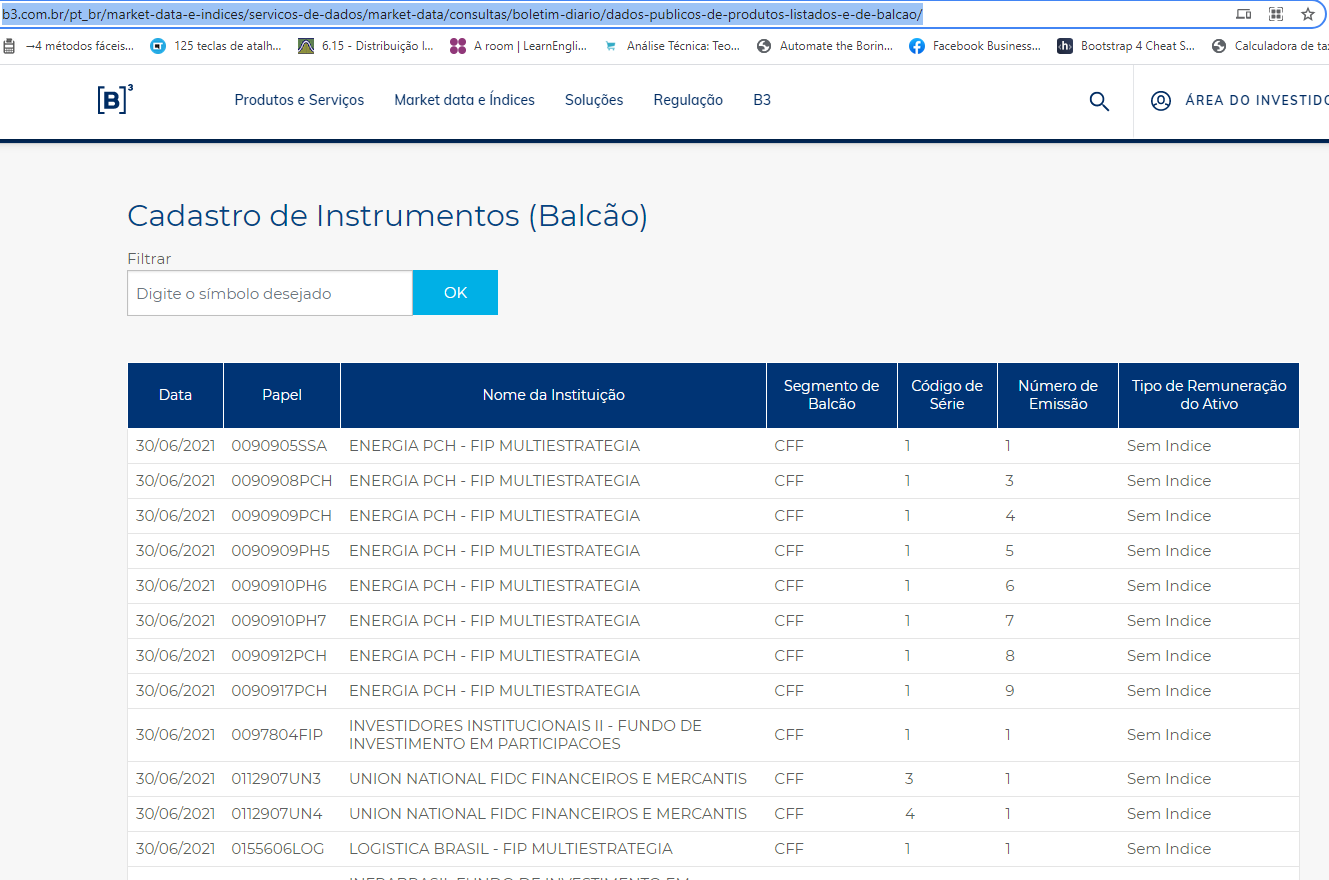
O site da B3 é um grande desafio quando se trata de extração de informações. Esse site contém vários iframes dentro do código original, ou seja, possui uma inclusão de outros arquivos HTML dentro do HTML original. Nisso, a função read_html só funciona em casos onde o código fonte da página mostre as tags table, mas nesse caso, esse site é carregado dinamicamente, o que faz com que o código seja gerado na medida com que requisitamos as páginas, por isso não foi encontrada a tabela. Para resolver casos como esse, geralmente utilizamos uma técnica denominada web scraping, que é onde fazemos algumas operações automáticas para encontrar elementos específicos dentro de um site e isso pode ser a tabela completa, apenas um título ou até mesmo fazer downloads automáticos através de um evento de clique. Mas, para resolver esse problema que você apresentou, sugiro uma outra abordagem. Observe que no canto inferior esquerdo da página é disponibilizado um arquivo csv completo com as informações, baixe esse arquivo e faça a leitura dele através da função read_csv do pandas, veja como fica em código:
import pandas as pd
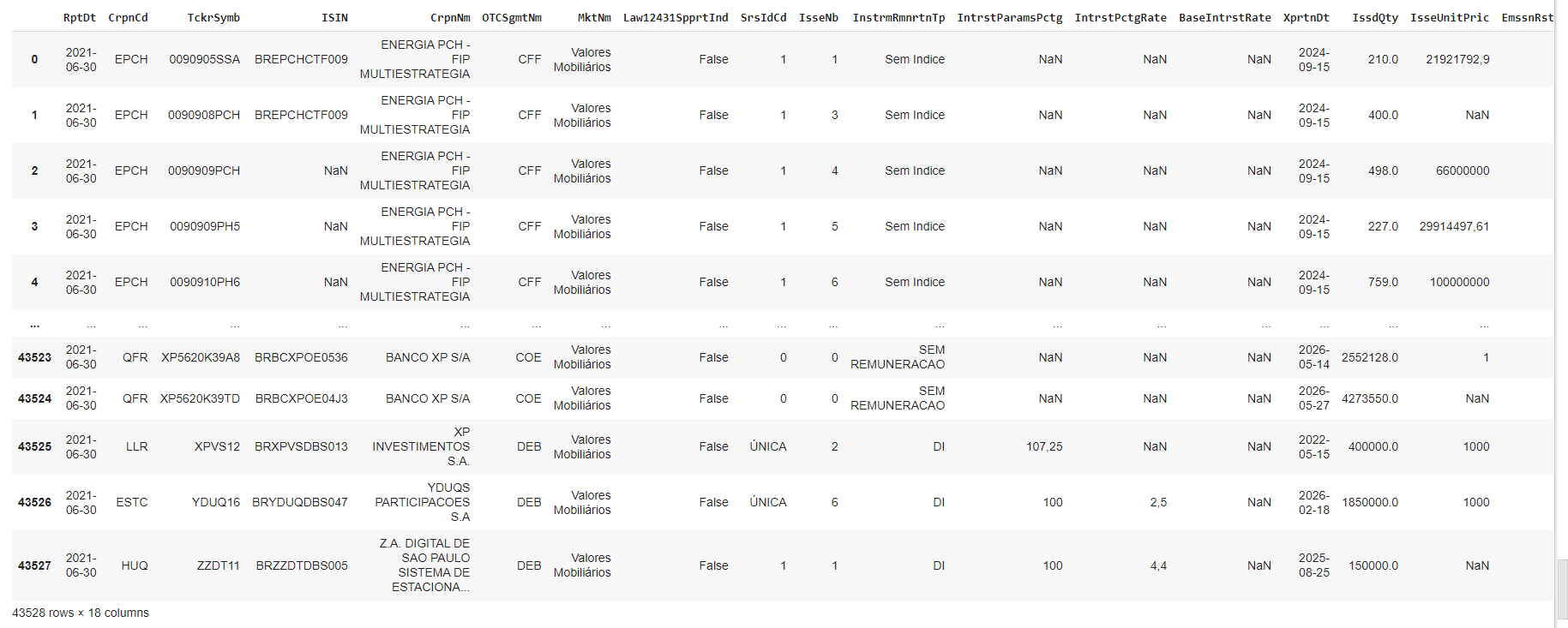
dados = pd.read_csv('OTCInstrumentsConsolidatedFile_20210630_1.csv', encoding = "ISO-8859-1", delimiter=';')
dadosCom isso, vamos obter o resultado completo em forma de tabela (os valores NaN demonstram ausência de valor):
E caso precise acessar alguma coluna especifica, a sintaxe é a mostrada a seguir:
dados['RptDt']Caso queira conhecer um pouco mais sobre a técnica de web scraping, sugiro o curso de Scraping com Python: Coleta de dados na web que dará uma aprofundada sobre esse assunto.
Qualquer dúvida estou à disposição.
Grande abraço!
Bom dia, Nádia! Muito obrigado pela sua explicação. Foi bastante esclarecedora sua explicação. O problema é que eu precisava fazer isso de forma automática. E todos os dias eles mudam o arquivo.
Vou te ensinar a fazer de forma automática, Ubiratan.
A ideia geral é que o nosso código consiga acessar a página da B3 e clicar no botão para fazer o download do arquivo .csv de forma automática e após isso, direcionamos esse arquivo para o pandas efetuar a leitura.
Antes de prosseguirmos, precisamos configurar nosso ambiente, pois não iremos utilizar o Google Colab. Então vamos lá:
Passo 1 - Crie uma pasta vazia para o projeto em seu computador.
Passo 2 - Baixe o Python em sua máquina:
Passo 3 - Baixe um editor de código. Eu particularmente utilizo o VSCode, então deixarei o link de download dele logo abaixo:
Passo 4 - Baixe o navegador Google Chrome, pois utilizaremos ele para essa automação:
Passo 5 - Com o Chrome baixado, abra-o. No canto superior direito clique nos três pontinhos e vá até Configurações:

Passo 6 - Agora, clique em Sobre o Google Chrome e na tela que se abrir, verifique qual versão você está utilizando, no meu caso, é a 91.0.4472.124. Guarde isso, pois será importante para o próximo passo:

Passo 7 - Acesse a página de webdriver do Google Chrome e escolha um que seja semelhante a versão do seu navegador. Por exemplo: eu terei que escolher algum dos arquivos que possuam a versão 91, pois essa é a versão do meu Google Chrome e na tela que se abrir, selecione o arquivo .zip de seu sistema operacional:

Um webdriver é um arquivo responsável por auxiliar na automatização da página, entenda como se fosse um "mini navegador" que irá executar por baixo dos panos do Google Chrome para abrir a página e fazer o download automático do arquivo.
Passo 8 - Será baixado um arquivo .zip e dentro dele terá um arquivo .exe, copie esse arquivo para dentro da pasta inicial do projeto que criamos no passo 1.
Passo 9 - Por fim, vamos instalar a biblioteca que iremos utilizar, a selenium. Abra o terminal (ou prompt de comando no caso do windows) e digite:
pip install seleniumE não menos importante, a biblioteca pandas:
pip install pandasPronto, temos o nosso ambiente configurado, podemos partir para o código.
Continua na próxima resposta...
Abra o VSCode e em File, selecione Open Folder e abra a pasta inicial que criamos no passo 1. Após isso, crie um arquivo denominado main.py.
Quanto ao código, teremos o seguinte:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="C:\\Users\\olive\\Documents\\Alura\\chromedriver.exe")
driver.implicitly_wait(10)
driver.get("https://arquivos.b3.com.br/tabelas/OTCInstrumentsConsolidated/2021-06-30?lang=pt")
tabela = driver.find_elements_by_link_text("Baixar arquivo completo")
tabela[0].click()Vamos entender linha a linha o que este código está fazendo. Primeiramente, importamos da biblioteca selenium o webdriver para conseguirmos utilizar o .exe que baixamos:
from selenium import webdriverPosteriormente, criamos uma instância do navegador Chrome através do .exe que baixamos e para isso, é necessário passar o caminho completo da pasta onde se localiza o .exe:
driver = webdriver.Chrome(executable_path="C:\\Users\\olive\\Documents\\Alura\\chromedriver.exe")Quanto ao trecho driver.implicitly_wait(10) é para que o código espere 10 segundos para pesquisar algo na página até que o carregamento dinâmico do código seja feito.
Em tabela = driver.find_elements_by_link_text("Baixar arquivo completo") procuramos pelo link que esteja escrito Baixar arquivo completo, que se refere a essa parte da página:

Um ponto importante sobre o driver.find_elements_by_link_text é que ele retorna uma lista de elementos, por isso a necessidade da próxima linha conter a posição 0, e juntamente a ela, clicamos no link através do atributo click.
Em meu computador, por padrão os arquivos são baixados na pasta de download, então para ler os dados com o pandas o código fica da seguinte forma:
import pandas as pd
from selenium import webdriver
import time
wd = webdriver.Chrome(executable_path="C:\\Users\\olive\\Documents\\Alura\\chromedriver.exe")
wd.implicitly_wait(10)
wd.get("https://arquivos.b3.com.br/tabelas/OTCInstrumentsConsolidated/2021-06-30?lang=pt")
tabela = wd.find_elements_by_link_text("Baixar arquivo completo")
tabela[0].click()
# Para esperar o arquivo baixar
time.sleep(25)
dataframe = pd.read_csv("C:\\Users\\olive\\Downloads\\OTCInstrumentsConsolidatedFile_20210630_1.csv", encoding = "ISO-8859-1", delimiter=';')
print(dataframe)Prontinho! Toda vez que precisar acessar essa tabela basta executar esse código através do comando python main.py. O tempo de execução em minha máquina foi de aproximadamente um minuto.
Não sei se você tem costume de utilizar o próprio computador para programar em Python ou se já estava habituado com o Colab, mas a grande diferença, é que no Colab conseguiremos ver o resultado das operações imediatamente, e em nossa máquina será necessário executar o código e adicionar a variável ao comando print para ver o resultado dela. Para automações com o Selenium, o Google Colab não é tão recomendado. Mas já adianto que mercado financeiro e Selenium é uma ótima junção, principalmente para robôs Trader.
Caso seja necessário executar o código todos os dias em um determinado horário, recomendo que crie um agendamento de tarefas no Windows para que evite a necessidade de você executar manualmente o código.
A título de consultas futuras, deixo aqui a documentação do Selenium.
Sei que foram muitos passos e informações, mas qualquer dúvida que houver, fique à vontade. Estou à disposição.
Grande abraço!
Nádia, não sei nem como te agradecer pela sua atenção e ajuda. Poxa, eu venho buscando isso no stack e em outros lugares, mas não consegui juntar as peças. Valeu demais!!!!! Na verdade, eu comecei a fazer um curso de Selenium, mas estou bem no início. Eu uso o VS mesmo e o Jupyter dentro dele também.
Sempre gosto de já testar dentro do meu modelo pra entender onde estou errando e aprender. Neste caso, mudei pra Firefox, pois já uso esse webdriver e, claro, coloquei a path do meu VS. O código ficou assim:
import pandas as pd
from selenium.webdriver import Firefox
import time
wd = Firefox()
wd.implicitly_wait(10)
wd.get("https://arquivos.b3.com.br/tabelas/OTCInstrumentsConsolidated/2021-06-30?lang=pt")
tabela = wd.find_elements_by_link_text("Baixar arquivo completo")
tabela[0].click()
# Para esperar o arquivo baixar
time.sleep(25)
dataframe = pd.read_csv(r'C:\Users\usmei\Projetos Python\OTCInstrumentsConsolidatedFile_20210630_1.csv', encoding = 'ISO-8859-1', delimiter=';')
print(dataframe)Vi a página sendo aberta e o selenium clicando pra baixar o arquivo, mas esse arquivo não deveria ser gravado na minha pasta antes do comando de abrir como dataframe? Tô dizendo pois acabei recebendo um 'FileNotFoundError':
FileNotFoundError: [Errno 2] No such file or directory: C:\Users\usmei\Projetos Python\OTCInstrumentsConsolidatedFile_20210630_1.csv'Ubiratan, fico feliz que já esteja se inteirando a respeito do Selenium, é uma ferramenta que sem dúvidas te ajudará muito em relação ao mercado financeiro. Quanto ao uso do Firefox, fique tranquilo, existe webdriver para vários navegadores, então fica a critério de qual utilizar, eu particularmente uso muito o Google Chrome, por isso fiz o tutorial a partir dele.
Isso, quando fazemos o comando time.sleep(25) é para que dê o tempo suficiente do arquivo ser baixado, então, ao chegar nessa instrução o código esperará 25 segundos e após isso irá para a próxima instrução de abertura do dataframe. Recomendo que aumente um pouco esse tempo, pois em minha máquina 25 segundos foi suficiente, mas, pode ocorrer de não ser o mesmo tempo na sua. Recomendo que dobre essa quantidade de tempo ou teste com valores maiores, exemplo:
time.sleep(50)Outra opção que temos para evitar um "chute" de tempo, é fazermos um laço de repetição para que o código não vá para a próxima instrução até que o arquivo exista na pasta e após isso, fazemos a leitura. No caso em particular do Firefox, é comum que uma janela seja aberta perguntando se deseja abrir o arquivo ou salvá-lo, como mostro abaixo:

Isso impossibilita a automatização completa deste código pelo Firefox, sendo necessário clicar manualmente para salvar o arquivo, mas, para evitar que essa janela seja aberta, adicione as seguintes configurações:
profile = webdriver.FirefoxProfile() # Para alterar as configurações do navegador
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", 'application/octet-stream') # Impede que a janela seja aberta para o arquivo
wd = webdriver.Firefox(firefox_profile=profile)Dessa forma, será feito o download automático do arquivo.
Outro ponto importante: Caso você precise fazer download deste mesmo arquivo todos os dias, é necessário apagá-lo (os.remove) após fazer as análises, pois, caso contrário terá um cenário onde o arquivo mais atual nunca será lido, pois teremos vários arquivos com o mesmo nome dentro da pasta, como mostro na imagem a seguir:

Observe que o arquivo mais atual consta no nome o (1) e se baixássemos outro, teria o (2) e assim por diante.
Abaixo o código completo com as modificações e em seguida um vídeo demonstrando o funcionamento:
from selenium import webdriver
import pandas as pd
import time, os
profile = webdriver.FirefoxProfile() # Para alterar as configurações do navegador
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", 'application/octet-stream') # Impede que a janela seja aberta para o arquivo
wd = webdriver.Firefox(firefox_profile=profile)
wd.implicitly_wait(10)
wd.get("https://arquivos.b3.com.br/tabelas/OTCInstrumentsConsolidated/2021-06-30?lang=pt")
tabela = wd.find_elements_by_link_text("Baixar arquivo completo")[0].click()
arquivo = "C:\\Users\\olive\\Downloads\\OTCInstrumentsConsolidatedFile_20210630_1.csv"
# Enquanto o arquivo não existir, não faça nada
while not os.path.isfile(arquivo):
pass
# Espere o arquivo ficar totalmente disponível na pasta
time.sleep(5)
# Faça a leitura do arquivo
dataframe = pd.read_csv(arquivo, encoding = "ISO-8859-1", delimiter=';')
print(dataframe)
os.remove(arquivo)
wd.close()Qualquer dúvida estou à disposição.
Abraços!
Ei, Nádia! Você é nota 1000, hein menina?! Eu fiquei com algumas dúvidas. Com o Firefox o máximo da automação é gerar aquele arquivo de download, certo? Se eu usar o chrome tudo fica automatizado, não é isso? Mais uma coisa, com o chrome também preciso daquele instrução do os? Muito obrigado!
Nádia, eu estou tentando rodar com o chrome mesmo. Fiz do jeito que você falou, mas já coloquei o chromedriver.exe na pasta dos meus projetos, que é a 'PROJETOS PYTHON' como você pode ver na figura.
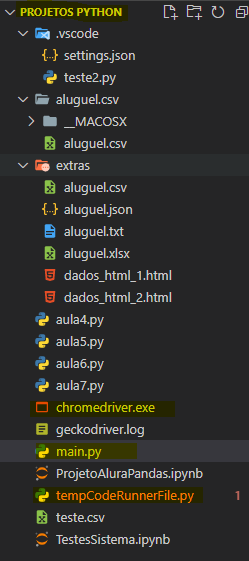
Então, copiei a path do chromedriver.exe, que é: 'C:\Users\usmei\Projetos Python\chromedriver.exe' e troquei a executable_path que você passou por essa.
Em dataframe = pd_read_csv, coloquei a path "C:\Users\usmei\Projetos Python\OTCInstrumentsConsolidatedFile202106301.csv". Como você pode ver, foi gerado um arquivo temporário. Mas, no final, obtive dois erros:
"C:\Users\usmei\Projetos Python\OTCInstrumentsConsolidatedFile202106301.csv" e "C:\Users\usmei\Projetos Python\OTCInstrumentsConsolidatedFile202106301.csv".
Será que você pode continuar me ajudando? Desculpe, mesmo mastigando tudo, ainda fiz caca rsrs.
Eiiii Ubiratan, posso continuar auxiliando sim.
Em ambos você conseguirá a automação completa, porém, no Firefox tem a janela que mostrei nos prints, onde ela pergunta se desejamos salvar ou abrir o arquivo, e para contornar isso, utilizamos aquele trecho de código que eu havia mostrado:
profile = webdriver.FirefoxProfile() # Para alterar as configurações do navegador
profile.set_preference("browser.helperApps.neverAsk.saveToDisk", 'application/octet-stream') # Impede que a janela seja aberta para o arquivo
wd = webdriver.Firefox(firefox_profile=profile)Não necessariamente, ela é apenas para não chutarmos um tempo para esperar que o download do arquivo seja feito, porque isso pode variar de máquina para máquina. Por exemplo: na minha eu esperei em média 25 segundos, mas pode acontecer de na sua ser mais ou menos que esse valor. Com a instrução do os fica melhor por não precisarmos chutar esse valor, entende?! O código com o os para o Chrome fica assim:
import pandas as pd
from selenium import webdriver
import time, os
wd = webdriver.Chrome(executable_path="C:\\Users\\olive\\Documents\\Alura\\chromedriver.exe")
wd.implicitly_wait(10)
wd.get("https://arquivos.b3.com.br/tabelas/OTCInstrumentsConsolidated/2021-06-30?lang=pt")
tabela = wd.find_elements_by_link_text("Baixar arquivo completo")[0].click()
arquivo = "C:\\Users\\olive\\Downloads\\OTCInstrumentsConsolidatedFile_20210630_1.csv"
# Enquanto o arquivo não existir, não faça nada
while not os.path.isfile(arquivo):
pass
# Espere o arquivo ficar totalmente disponível na pasta
time.sleep(5)
# Faça a leitura do arquivo
dataframe = pd.read_csv(arquivo, encoding = "ISO-8859-1", delimiter=';')
print(dataframe)
os.remove(arquivo)
wd.close()No meu caso, o Chrome está configurado para salvar os arquivos na pasta de Downloads:
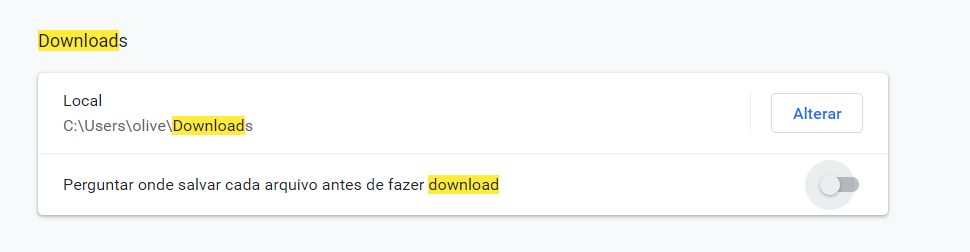
Por isso o caminho do arquivo .csv é o de Downloads, verifique qual caminho está nas configurações do seu Chrome para não ocorrer erro de arquivo inexistente.
Os erros que você apresentou, não fica claro o porque eles estão acontecendo, o que você postou é apenas o caminho de alguns arquivos. Se puder executar o código e tirar um print do erro sendo gerado poderei te ajudar melhor.
Fico no aguardo.
Nádia, tudo bem? Nossa, fiquei tão feliz hoje rsrs. Eu refiz, passo a passo, tudo o que você me ensinou e deu certo. Eu estava falhando no caminho do download mesmo. Já consegui transformar os dados em um dataframe. Nem acredito! Muita gratidão a você por isso!
Infelizmente, ainda tenho umas dúvidas: se todos os dias a B3 carrega um novo arquivo do pregão anterior, como consigo automatizar isso, pois o link é sempre o mesmo, não?
Quanto ao os.remove que você me disse pra usar, estou pensando em, antes de remover, enviar o arquivo pro meu BD.
Estou tentando praticar com outras páginas. Até eu entender direitinho, ainda vou te amolar. Por favor, me perdoe. Você foi a única pessoa que encontrei que conseguiu me ajudar com isso.
Tentei entrar nessa outra página da B3.
wd = webdriver.Chrome(executable_path=r"C:\Users\usmei\Projetos Python\automacao\chromedriver.exe")
wd.implicitly_wait(10)
wd.get("http://www.b3.com.br/pt_br/market-data-e-indices/servicos-de-dados/market-data/consultas/mercado-a-vista/participacao-dos-investidores/volume-total-acumulado-mensal/")
tabela = wd.find_elements_by_link_text("Download")
tabela[0].click()
# Para esperar o arquivo baixar
time.sleep(25)
dataframe = pd.read_csv(r"C:\Users\usmei\Downloads\volumeTotalAcumuladoMensal.csv", encoding = "ISO-8859-1", delimiter=';')
dfx = pd.DataFrame(dataframe)
print(dfx)Obtive o seguinte resultado:
wd = webdriver.Chrome(executable_path=r"C:\Users\usmei\Projetos Python\automacao\chromedriver.exe")
wd.implicitly_wait(10)
wd.get("http://www.b3.com.br/pt_br/market-data-e-indices/servicos-de-dados/market-data/consultas/mercado-a-vista/participacao-dos-investidores/volume-total-acumulado-mensal/")
tabela = wd.find_elements_by_link_text("Download")
tabela[0].click()
# Para esperar o arquivo baixar
time.sleep(25)
dataframe = pd.read_csv(r"C:\Users\usmei\Downloads\volumeTotalAcumuladoMensal.csv", encoding = "ISO-8859-1", delimiter=';')
dfx = pd.DataFrame(dataframe)
print(dfx)Quando tiro o tabela[0].click(), ele volta a dar um erro de diretório. Se puder continuar me ajudando, ficarei muito feliz. Por fim, você sempre faz um download manual e copia o nome do arquivo, certo?
Oiiii Ubiratan, como você está?
Tive alguns imprevistos, por isso a demora em retornar, me desculpe.
Fico muito feliz que você tenha conseguido fazer a leitura.
Isso, o link é sempre o mesmo e o nome do arquivo também. Uma forma de automatizar esse processo é agendar no agendador de tarefas do windows um horário fixo para que o arquivo python seja executado automaticamente. Por exemplo: todo dia às 10:00 da manhã o código será executado. Sendo assim, você não precisará ter que abrir manualmente o código e executá-lo. Seria esse tipo de automatização que você se refere? Caso não seja, me dê um exemplo para que eu possa te auxiliar melhor.
É uma boa opção para manter o backup dessa informação. Aqui temos duas abordagens dentro do banco: estruturar um banco com todas as colunas do arquivo csv ou então, salvar apenas o endereço físico do arquivo de backup. Caso precise de ajuda nessa parte, abra um novo tópico especificando qual banco você está utilizando que ensino o passo a passo para você salvar o arquivo por lá.
Fique tranquilo quanto a isso, fico muito feliz de poder compartilhar o conhecimento e te ajudar de alguma forma.
Ubiratan, a B3 tem uma estrutura que muita das vezes varia de página para página, por isso o scraping nesse site é desafiador. Um padrão muito comum desse site é estruturar as páginas dentro de iframe, que como disse inicialmente é um código HTML dentro de outro e se analisarmos essa nova página que você está testando, veremos que há um iframe inserido nela, veja:
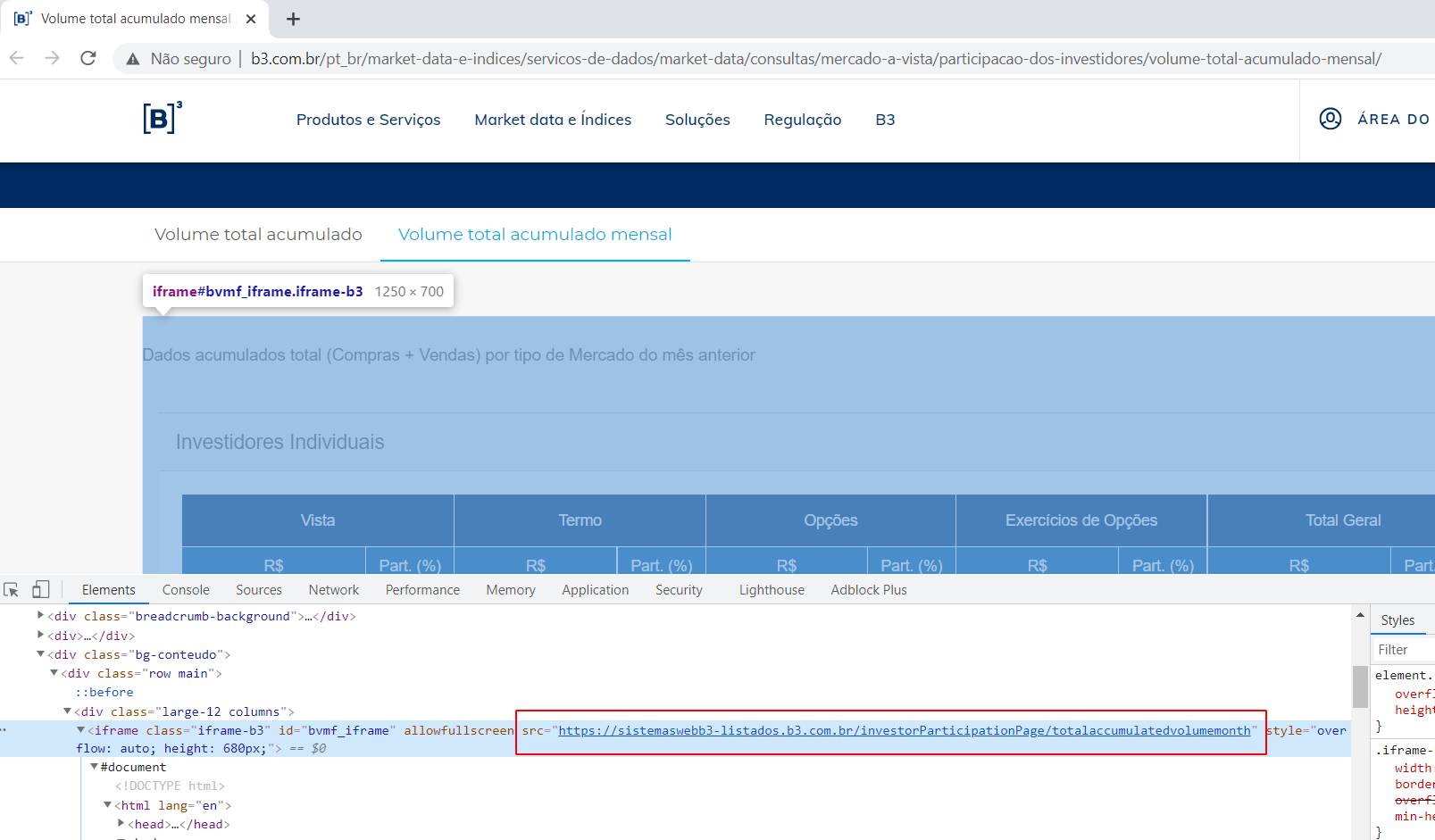
Isso quer dizer que essa tabela que vemos nesse link principal que você está utilizando, na verdade é um código de outra página e o link dela está dentro do atributo src.
Em outras palavras: para o seu scraping funcionar, temos que utilizar o link do iframe, que é o código original da tabela e que consta o botão de download, como mostro abaixo:
wd.get("https://sistemaswebb3-listados.b3.com.br/investorParticipationPage/totalaccumulatedvolumemonth")Basta alterar isso em seu código e deverá funcionar como esperado.
Isso, a ideia do código é efetuar o download e utilizar o arquivo baixado.
Qualquer dúvida fico à disposição.
Grande abraço e uma boa semana!
Ei, Nádia! Tudo bem comigo e com você?
Só de responder, já fico feliz! Quanto ao lance da automatização, estava me referindo ao seguinte: uma vez que o arquivo terá sempre o mesmo nome e estará sempre no mesmo link, no caso do selenium, não vou sempre correr o risco de estar pegando o mesmo arquivo em vez do novo que foi colocado?
Eeeei Ubiratan, nesse caso, você sempre pegará o mais recente, pois mesmo que seja o mesmo link e o mesmo nome, esse link e o nome armazenará os dados mais recentes, pois a B3 só sobrescreve o que já existe, mesmo que seja um novo arquivo, ele estará no mesmo link. Entende?
Qualquer dúvida fico à disposição.
Grande abraço!
Ah, entendi!
Eu fiz as alterações pegando no iframe, mas os dados não vieram em formato DataFrame, mesmo com o comando.
import pandas as pd
from selenium import webdriver
import time
import requests
wd = webdriver.Chrome(executable_path=r"C:\Users\usmei\Projetos Python\automacao\chromedriver.exe")
wd.implicitly_wait(10)
wd.get("https://sistemaswebb3-listados.b3.com.br/investorParticipationPage/totalaccumulatedvolumemonth")
tabela = wd.find_elements_by_link_text("Download")
tabela[0 ].click()
# Para esperar o arquivo baixar
time.sleep(25)
dataframe = pd.read_csv(r"C:\Users\usmei\Downloads\volumeTotalAcumuladoMensal.csv", encoding = "ISO-8859-1", delimiter=';')
**dfx = pd.DataFrame(dataframe)**
print(dfx)
O output veio assim:

Isso está ocorrendo por causa do delimitador desse arquivo csv, observe que temos o pipe (|) e não um ponto e vírgula (;) como no outro arquivo:
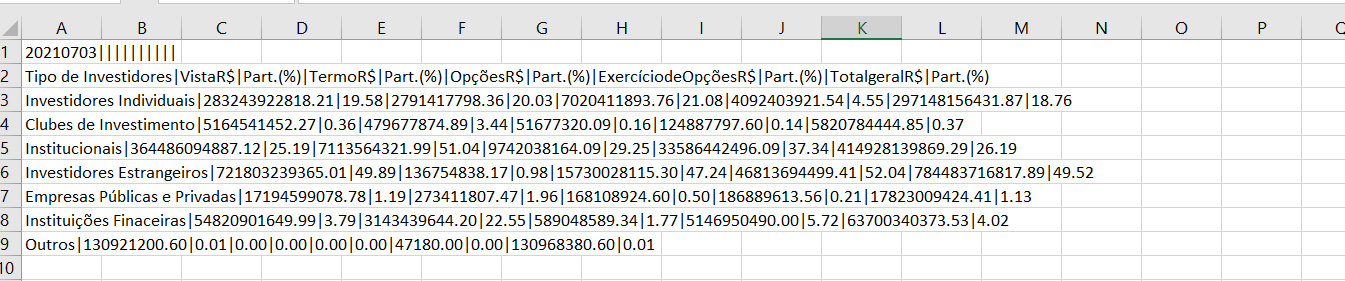
Se alterarmos o delimitador para o pipe, obteremos um dataframe como esperado:
dataframe = pd.read_csv(r"C:\Users\usmei\Downloads\volumeTotalAcumuladoMensal.csv", encoding = "ISO-8859-1", delimiter='|')Resultado:

Como algumas colunas deste arquivo csv não são nomeadas, isso se tornará Unnamed no dataframe.
Mas, caso você queira que a primeira linha do arquivo csv seja ignorada e as colunas sejam nomeadas a partir da segunda linha, basta passar o parâmetro skiprows=[0]:
pd.read_csv(r"C:\Users\usmei\Downloads\volumeTotalAcumuladoMensal.csv", encoding = "ISO-8859-1", delimiter='|', skiprows=[0])Isso resultará no seguinte dataframe:

Obs: Perdão não ter visto isso na resposta anterior.
Grande abraço!
Olá, Nádia! Tudo bem com você? Você disse que Selenium para dados do mercado é muito importante, né? Estou fazendo um curso, mas ele não está muito voltado pra webscraping. Você teria algum pra me indicar? Obrigado!
Nádia, tudo bem? Desistiu de mim? rsrs
Tô usando o selenium, mas, no final, embora consiga pegar todos os dados, não consigo transformá-los em um dataframe.
from selenium.webdriver import Firefox
import pandas as pd
import numpy as np
import csv
url = ('https://www2.bmf.com.br/pages/portal/bmfbovespa/lumis/lum-tipo-de-participante-ptBR.asp')
firefox = Firefox()
firefox.get(url)
# x = firefox.find_elements_by_tag_name('tr')
x = firefox.find_elements_by_id('divContainerIframeBmf')
print(x[0].text)
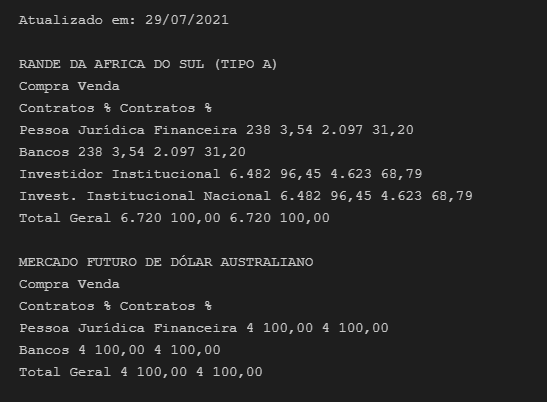 Quando faço um
Quando faço um
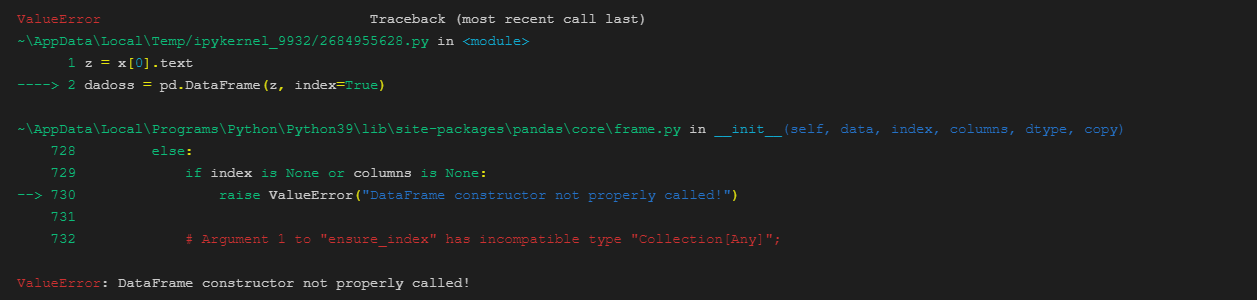
z = x[0].text
dadoss = pd.DataFrame(z)recebo a mensagem:
 Sinto que estou quase lá. Se puder continuar me ajudando, agradeço muito.
Sinto que estou quase lá. Se puder continuar me ajudando, agradeço muito.
Oiiii Ubiratan, não desisti não hahaha fique tranquilo, continuarei te auxiliando.
Claro, o primeiro material que recomendo é a própria documentação da biblioteca. O segundo, é uma playlist que contém exemplos práticos do uso dessa biblioteca. Deixo abaixo os links:
Uma dica que vale salientar, é que caso queira fazer algo muito específico e não encontre exemplos na documentação ou pesquisando em português, tente pesquisar em inglês, há muitos materiais bons na língua estrangeira (utilizando o recurso de tradução de páginas do próprio navegador é possível a compreensão).
Concorda comigo que um dataframe nada mais é que uma tabela? E uma tabela é constituída por linhas e colunas, certo? Da forma que você elaborou o código apenas passando um texto completo para o dataframe não tem como ele saber como organizar essa tabela, ou seja, ele não sabe os títulos da coluna, não sabe quais os valores das linhas, tudo que ele tem é apenas um texto que foi colocado nele e por isso do erro. Por padrão, um dataframe espera receber como parâmetro um dicionário ou qualquer outro iterável, como uma lista por exemplo.
Dito isso, para converter os seus dados em um DataFrame é necessário primeiro estruturar esses dados, ou seja, dizer quais são os valores das linhas, colunas. Exemplo:
import pandas as pd
dados_iniciais = {
"RANDE DA AFRICA DO SUL (TIPO A)": {
"Pessoa Jurídica Financeira": [0, 0.00, 3.995, 90.28],
"Bancos": [0, 0.00, 3.995, 90.28],
"Investidor Institucional": [4.425, 100.00, 430, 9.71],
"Invest. Institucional Nacional": [4.425, 100.00, 430, 9.71],
"Total Geral": [4.425, 100.00, 4.425, 100.00]
},
"MERCADO FUTURO DE DÓLAR AUSTRALIANO": {
"Pessoa Jurídica Financeira": [4, 100.00, 4, 100.00],
"Bancos": [4, 100.00, 4, 100.00],
"Total Geral": [4, 100.00, 4, 100.00]
},
}
dados_refatorados_para_dataframe = {}
for chave_externa, dicionario in dados.items():
for chave_interna, valor in dicionario.items():
dados_refatorados_para_dataframe[(chave_externa, chave_interna)] = valor
df = pd.DataFrame(dados_refatorados_para_dataframe)
Resultado:

Observe que teremos um DataFrame que tem como nome das colunas o nome do participante e para acessar os dados do participante específico, basta acessarmos da seguinte forma:
df["MERCADO FUTURO DE DÓLAR AUSTRALIANO"]
df["MERCADO FUTURO DE DÓLAR AUSTRALIANO"]["Bancos"]Quanto a organização dos números, ela segue uma ordem:
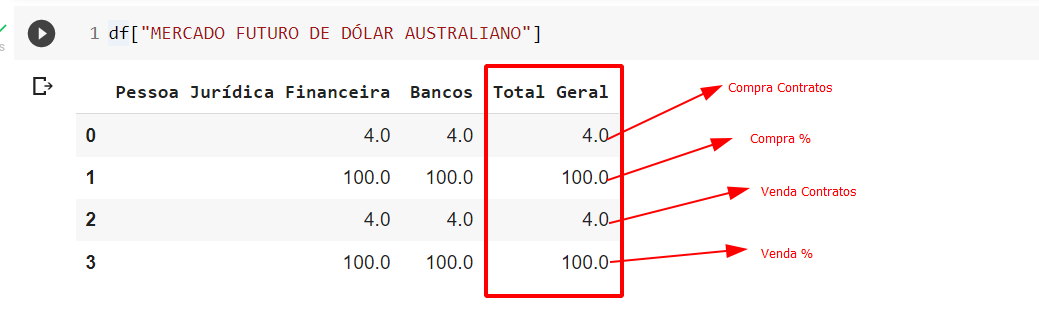
Em relação ao código utilizado para manipulação dos dados, ele foi necessário pelo fato de possuirmos um dicionário dentro do outro para que a estrutura fosse criada da forma desejada.
Obs: Estruturar uma tabela do pandas da forma exata como está na página da B3 se torna algo extremamente complexo, por isso das adaptações. A forma como eu estruturei é apenas um exemplo, fica a seu critério de organização uma outra forma que vá encaixar melhor para o seu caso de uso.
Agora, precisamos adaptar o seu scraping para que ele adquira as informações de forma separada, de modo a nos possibilitar a construção de um dicionário com os dados e não que adquira todo o texto de uma só vez. Para isso, será necessário buscar as tags de interesse na página e isso, deixarei como desafio para você.
Qualquer dúvida fico à disposição.
Grande abraço e bons estudos!
Eiiii, Nádia!!!! Tudo bem? O Leonardo falou pra mim que você não tinha desistido rsrss. Que ótimo! Muita gratidão!
Bem, eu fiquei com uma dúvida: para cada uma das tabelas eu vou ter que fazer o que fez para o Rande e para o Dólar ou eu posso fazer isso com for, pegando os dados pelas tags? Pois, você pegou dado por dado, na mão, pra elaborar os dicionários, certo?
Oiii Ubiratan, tudo certinho por aqui, espero que esteja com você também.
Eu peguei as informações manualmente (dado por dado) para exemplificar como seria a estrutura do dicionário e te mostrar como poderíamos adicionar esses dados ao dataframe. Fazer com o for pegando os dados pelas tags é a maneira recomendada, inclusive, foi esse o desafio que deixei para você. Mas, abaixo darei um pequeno spoiler que atende a sua necessidade:
from selenium.webdriver import Firefox
import pandas as pd
url = ('https://www2.bmf.com.br/pages/portal/bmfbovespa/lumis/lum-tipo-de-participante-ptBR.asp')
firefox = Firefox()
firefox.get(url)
tabelas = firefox.find_elements_by_tag_name("table")
dados = {}
dados_completos = {}
for tabela in tabelas:
nome_ativo = tabela.find_element_by_tag_name("caption")
nome_ativo = nome_ativo.text.title()
linhas_da_tabela = tabela.find_elements_by_tag_name("tr")
for linha in linhas_da_tabela:
conteudo_da_linha = linha.find_elements_by_tag_name("td")
if len(conteudo_da_linha) != 0:
titulo, compra_contrato, compra_percentual, venda_contrato, venda_percentual = conteudo_da_linha
dados[titulo.text] = [compra_contrato.text, compra_percentual.text, venda_contrato.text, venda_percentual.text]
dados_completos[nome_ativo] = dados
dados = {}
dados_refatorados_para_dataframe = {}
for chave_externa, dicionario in dados_completos.items():
for chave_interna, valor in dicionario.items():
dados_refatorados_para_dataframe[(chave_externa, chave_interna)] = valor
df = pd.DataFrame(dados_refatorados_para_dataframe)
print(df)
firefox.close()Resultado:

Importante: O código mostrado é apenas uma base que alcança o resultado proposto, há maneiras de melhorá-lo, por exemplo: converter os dados numéricos para float ou int, e aprimorar a estrutura do código em si.
Qualquer dúvida fico à disposição e caso venha a ter uma dúvida específica sobre web scraping mas que seja diferente de tudo que falamos aqui, peço que abra um novo tópico, dessa forma, você poderá ser auxiliado com maior rapidez pelo nosso time e além disso, ajudará outros alunos que tiverem a mesma dúvida e contribuindo também para o aprendizado deles.
Grande abraço e bons estudos!