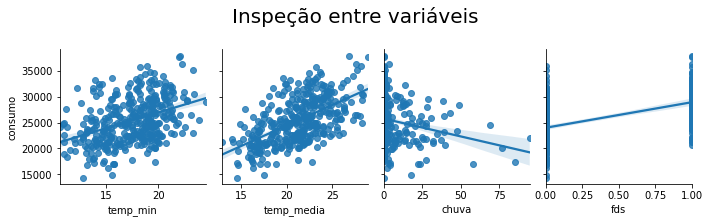
Bom dia. Estou tentando fazer uma análise estatística em um dataframe que montei com dados de saída de ferramentas em uma ferramentaria de manutenção. Meu espaço amostral ainda é bem pequeno, e minha contagem é feita por quantidade de ferramentas que saem por dia.
modelo = smf.ols(data=concatenacao, formula='cont_ferr ~ cont_oficinas + usuarios + cont_oficinas:usuarios')Quero associar o total de ferramentas que saem com a quantidade de oficinas operando no dia, e a quantidade de usuários, para no futuro fazer previsões de necessidade, pois o fluxo do número de pessoas é muito dinâmico e preciso desse ajuste. A minha dúvida é como faço para normalizar um experimento, que aparentemente é aleatório. Mais especificamente, como adapto um planejamento fatorial nesse experimento? Ou qual outra forma posso utilizar para colher um espaço amostral bom? Posso simplesmente fazer um cálculo de tamanho de amostra, usar o random.seed e um sample para sair coletando? Após isso faço o ztest e testo mais de uma amostra...