
Realizei um projeto na empresa ano passado em que acabamos num problema similar ao exemplo da instrutora. Tínhamos um conjunto de clusters com vários parâmetros e precisávamos explicar o significado de cada cluster para o cliente. Nós encontramos uma solução bem similar, mas mais estruturada. Como o processo precisava ficar rodando ad eternum no ambiente do cliente, criamos um algoritmo que, partindo das médias dos clusters, criava uma árvore de decisão. A ideia era:
- Partindo da base com os clusters e médias:
| clusters | BALANCE | PURCHASES | CASH_ADVANCE | CREDIT_LIMIT | PAYMENT |
|---|---|---|---|---|---|
| 0 | 444.41 | 628.83 | 143.42 | 5,130.73 | 814.02 |
| 1 | 3,045.59 | 387.06 | 1,625.21 | 4,495.43 | 967.48 |
| 2 | 1,142.07 | 3,268.80 | 183.84 | 4,094.43 | 3,046.70 |
| 3 | 1,797.74 | 466.45 | 3,286.53 | 3,985.95 | 4,667.18 |
| 4 | 1,985.92 | 855.01 | 423.19 | 2,228.00 | 1,345.66 |
- Usando média e desvio padrão das médias dos clusters, classificar casa média como alta (1), média (0) e baixa (-1):
| clusters | BALANCE | PURCHASES | CASH_ADVANCE | CREDIT_LIMIT | PAYMENT |
|---|---|---|---|---|---|
| 0 | -1 | 0 | -1 | 1 | -1 |
| 1 | 1 | 0 | 0 | 1 | 0 |
| 2 | 0 | 1 | -1 | 0 | 1 |
| 3 | 0 | 0 | 1 | 0 | 1 |
| 4 | 0 | 0 | -1 | -1 | 0 |
- Com isso, calculamos a variância das classificações de cada variável:
| BALANCE | PURCHASES | CASH_ADVANCE | CREDIT_LIMIT | PAYMENT |
|---|---|---|---|---|
| 0,5 | 0,2 | 0,8 | 0,7 | 0,7 |
- Assim, entendemos que a variável que mais separa os dados é CASH_ADVANCE. Logo, ela deve ser a primeira chave usada para separar os clusters:
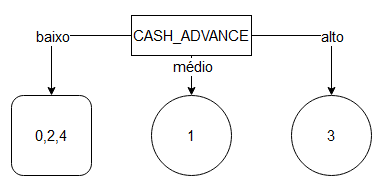 5) Com os clusters 1 e 3 separados, tiramos eles da tabela de clusters e recalculamos as variâncias, sem a CASH_ADVANCE:
5) Com os clusters 1 e 3 separados, tiramos eles da tabela de clusters e recalculamos as variâncias, sem a CASH_ADVANCE:
| BALANCE | PURCHASES | CREDIT_LIMIT | PAYMENT |
|---|---|---|---|
| 0,33 | 0,33 | 1 | 1 |
- Nesse cenário, tanto CREDIT_LIMIT quanto PAYMENT poderiam ser usados, pois apresentam a mesma variância e ela é a mais alta. Por ordem de aparição (poderia ser utilizado outro critério), utiilzamos a CREDIT_LIMIT como novo separador da árvore:
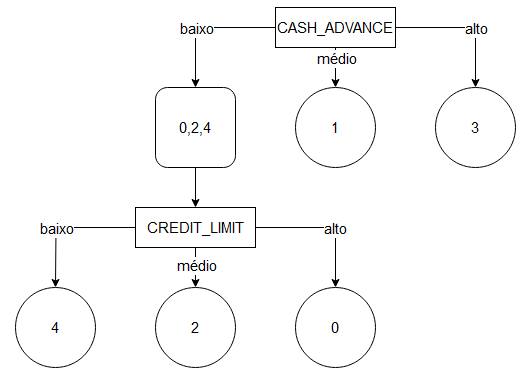
Com isso, tínhamos criado uma árvore de decisão para os clusters encontrados. O algoritmo é super simples, mas o cliente ficou super satisfeito com o resultado. Achei que valia a pena compartilhar aqui essa experiência! Alguém com alguma história parecida? Sugestões para esse algoritmo?

