
Resultado
Código
# Importa e instala o pacote necessário para a classificação zero-shot
!pip install -q -U liqfit sentencepiece
# Importação das bibliotecas necessárias
from liqfit.pipeline import ZeroShotClassificationPipeline # Pipeline para classificação zero-shot
from liqfit.models import T5ForZeroShotClassification # Modelo T5 para classificação zero-shot
from transformers import T5Tokenizer # Tokenizador da biblioteca Hugging Face
import pandas as pd # Biblioteca para manipulação de dados em formato de DataFrame
# Carrega o modelo T5 pré-treinado para classificação zero-shot
modelo = T5ForZeroShotClassification.from_pretrained('knowledgator/comprehend_it-multilingual-t5-base')
# Carrega o tokenizador T5 correspondente ao modelo
tokenizador = T5Tokenizer.from_pretrained('knowledgator/comprehend_it-multilingual-t5-base')
# Cria o pipeline de classificação zero-shot, configurando o modelo e o tokenizador
classificador = ZeroShotClassificationPipeline(model=modelo,
tokenizer=tokenizador,
hypothesis_template='{}', # Template usado para hipóteses (frases)
encoder_decoder=True) # Indica que o modelo é do tipo encoder-decoder
# Lê o arquivo CSV com descrições de produtos diretamente de uma URL e carrega em um DataFrame
dados = pd.read_csv('https://raw.githubusercontent.com/alura-cursos/hugging_face/main/Atividades/produtos_descricoes.csv')
# Define as categorias a serem usadas na classificação zero-shot
categorias = ['brinquedos', 'beleza', 'eletrônicos', 'ferramentas', 'cozinha']
# Função para classificar a descrição de um produto em uma das categorias definidas
def categorizar(descricao):
# Usa o pipeline de classificação para prever a categoria com base na descrição
resultado = classificador(descricao, categorias, multi_label=False)
# Identifica a categoria com a maior pontuação de confiança
categoria_max = max(zip(resultado['labels'], resultado['scores']), key=lambda x: x[1])[0]
# Retorna a categoria de maior probabilidade
return categoria_max
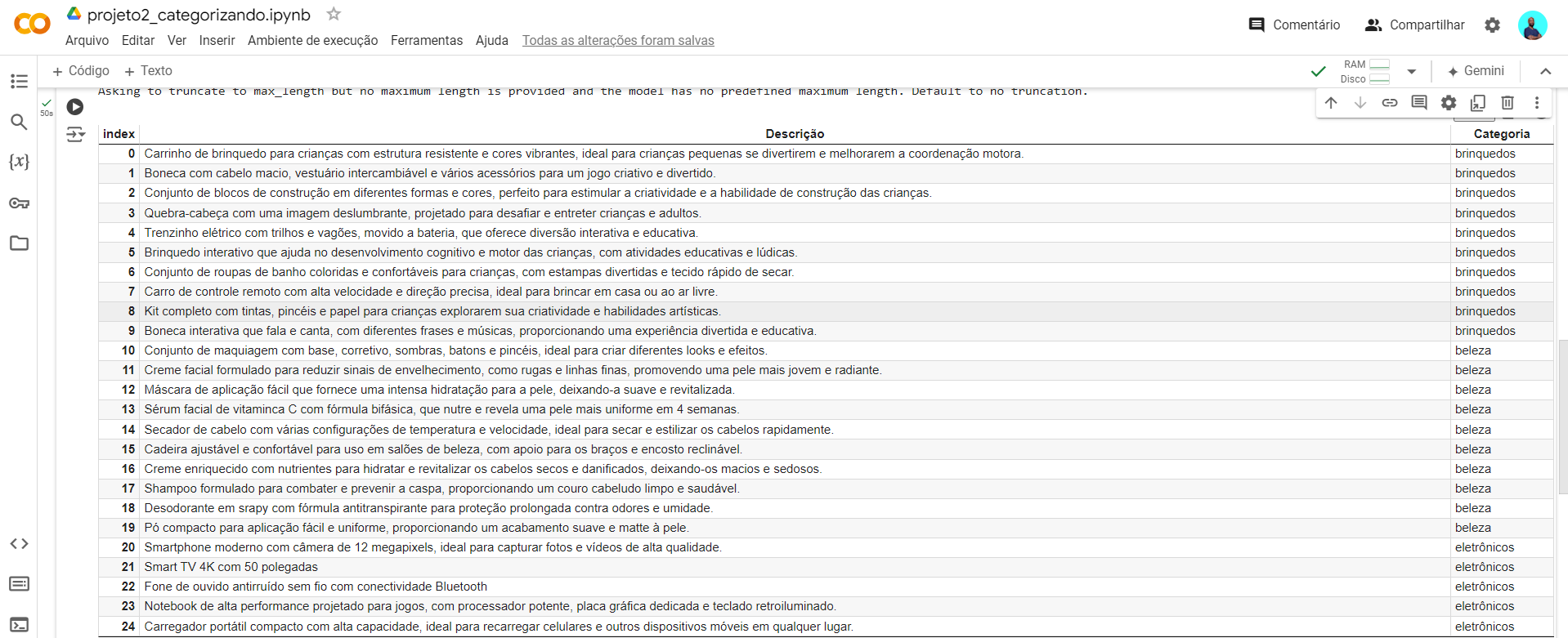
# Aplica a função de categorização a todas as descrições presentes na coluna 'Descrição'
dados['Categoria'] = dados['Descrição'].apply(categorizar)
# Exibe o DataFrame atualizado, agora contendo a coluna 'Categoria'
dados

