
Resultado do projeto
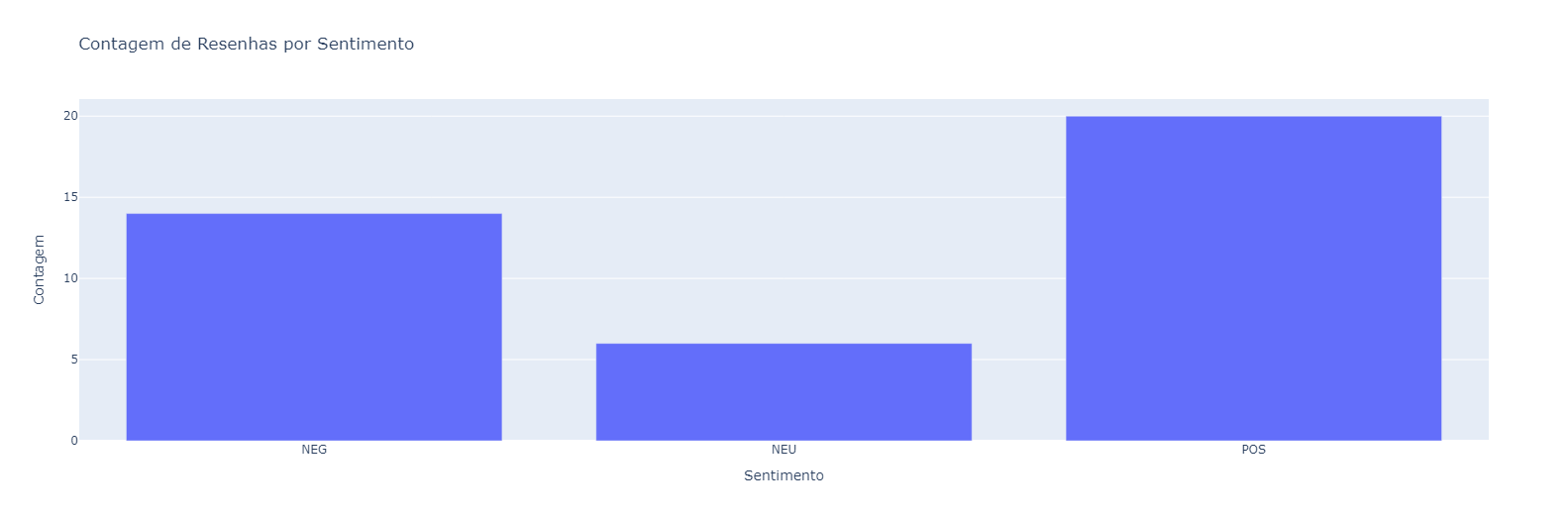
Gráfico para mostrar como estão os sentimentos dos clientes
Análise dos sentimentos positivos e negativos com uma nuvem de palavras (Wordcloud)
Palavras atribuídas ao sentimento positivo

Palavras atribuídas ao sentimento negativo

Código Python utilizado no Google Colab
# Instalar o pacote pysentimiento para análise de sentimentos
!pip install pysentimiento
# Importar a função create_analyzer do pysentimiento
from pysentimiento import create_analyzer
# Importar pandas para manipulação de dados
import pandas as pd
# Importar plotly express para visualizações gráficas
import plotly.express as px
# Importar nltk para processamento de linguagem natural
import nltk
# Importar stopwords em português do NLTK
from nltk.corpus import stopwords
# Importar WordCloud para gerar nuvens de palavras
from wordcloud import WordCloud
# Importar matplotlib para plotagem de gráficos
import matplotlib.pyplot as plt
# Criar um analisador de sentimentos para o idioma português
modelo_analise_sentimento = create_analyzer(task='sentiment', lang='pt')
# Carregar o conjunto de dados de resenhas de produtos
dados = pd.read_csv('https://raw.githubusercontent.com/alura-cursos/hugging_face/main/Atividades/resenhas_produto.csv')
# Realizar a previsão de sentimento para cada resenha
resultado_previsao = modelo_analise_sentimento.predict(dados['Resenha'])
# Exibir os resultados das previsões
resultado_previsao
# Extrair o sentimento (output) de cada previsão e armazenar na lista 'sentimento'
sentimento = [resultado.output for resultado in resultado_previsao]
# Adicionar a coluna 'Sentimento' ao DataFrame original
dados['Sentimento'] = sentimento
# Agrupar as resenhas por sentimento e contar a quantidade
df_sentimento = dados.groupby('Sentimento').size().reset_index(name='Contagem')
# Criar um gráfico de barras com a contagem de resenhas por sentimento
fig = px.bar(df_sentimento, x='Sentimento', y='Contagem',
title='Contagem de Resenhas por Sentimento')
# Exibir o gráfico
fig.show()
# Baixar as stopwords em português do NLTK
nltk.download('stopwords')
# Definir o conjunto de stopwords em português
portuguese_stopwords = set(stopwords.words('portuguese'))
def nuvem_palavras(texto, coluna_texto, sentimento):
"""
Gera e exibe uma nuvem de palavras para as resenhas de um determinado sentimento.
Parâmetros:
- texto: DataFrame contendo as resenhas e os sentimentos
- coluna_texto: Nome da coluna que contém o texto das resenhas
- sentimento: Sentimento a ser filtrado ('POS' para positivo, 'NEG' para negativo)
"""
# Filtrar as resenhas com base no sentimento especificado
texto_sentimento = texto.query(f"Sentimento == '{sentimento}'")[coluna_texto]
# Unir todas as resenhas em uma única string
texto_unido = " ".join(texto_sentimento)
# Dividir o texto em palavras e remover as stopwords
palavras = texto_unido.split()
palavras_filtradas = [palavra for palavra in palavras if palavra.lower() not in portuguese_stopwords]
texto_filtrado = " ".join(palavras_filtradas)
# Criar e exibir a nuvem de palavras
nuvem_palavras = WordCloud(width=800, height=500, max_words=50).generate(texto_filtrado)
plt.figure(figsize=(10, 7))
plt.imshow(nuvem_palavras, interpolation='bilinear')
plt.axis('off')
plt.show()
# Gerar a nuvem de palavras para resenhas positivas
nuvem_palavras(dados, 'Resenha', 'POS')
# Gerar a nuvem de palavras para resenhas negativas
nuvem_palavras(dados, 'Resenha', 'NEG')

