Boas Danival!
Tudo bem? Espero que sim!
De forma geral, não é um problema que as colunas tenham o dtype Object strings por padrão são objetos para o pandas.
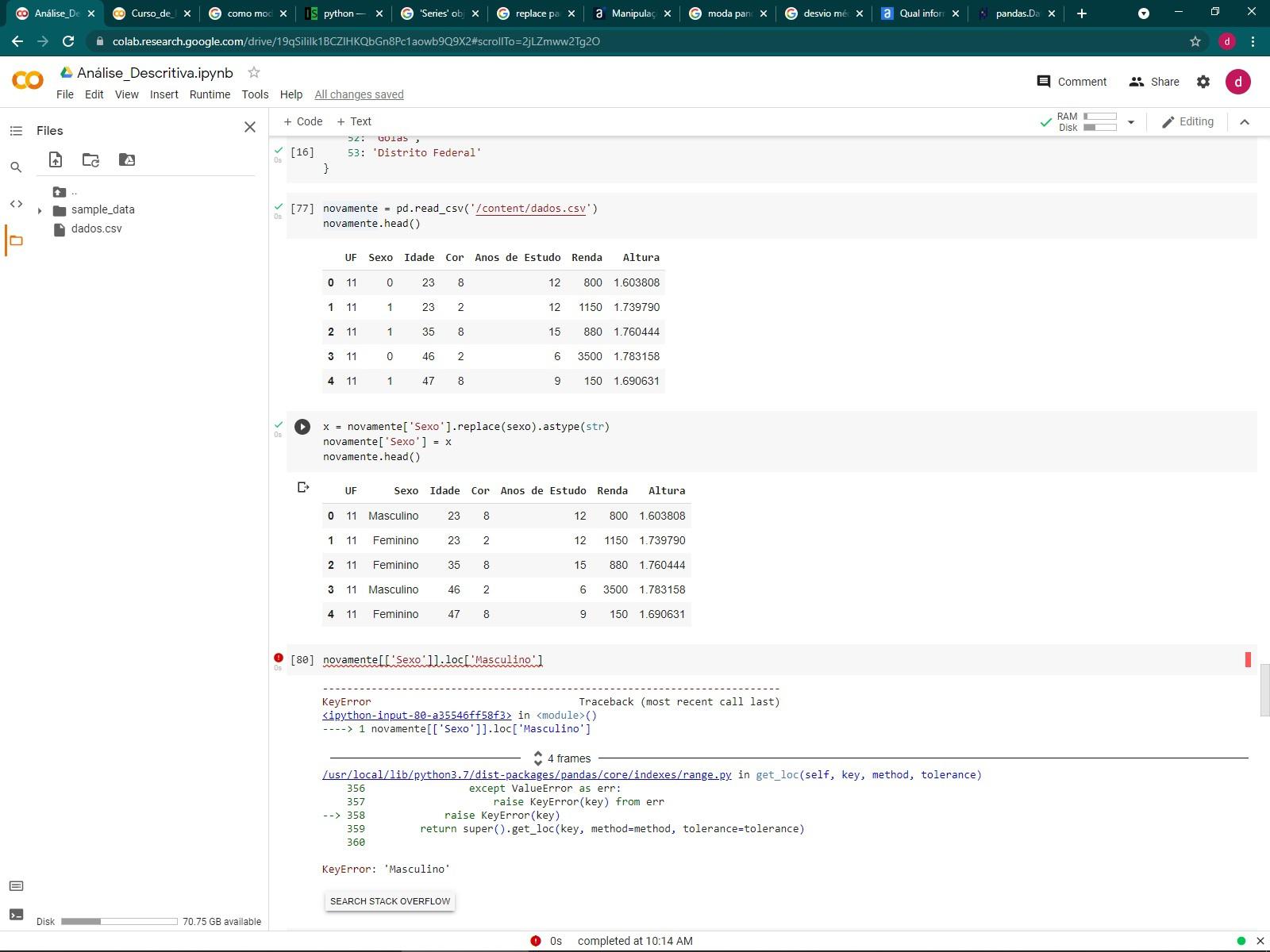
Eu não consegui identifcar o erro pelos prints que você mandou, então irei passo à passo para gerar as tabelas de frequência.
Primeiro, vou usar a função map para trocar os valores numéricos para strings:
sexo = {
0: 'Feminino',
1:"Masculino"
}
dados.Sexo = dados.Sexo.map(sexo)
Para a variável sexo, e:
cores = {
0:'Indígena',
2: 'Branca',
4: 'Preta',
6: 'Amarela',
8: 'Parda',
9: 'Sem declaração'
}
dados.Cor = dados.Cor.map(cores)
Agora, nosso dataframe está da seguinte forma:
| UF | Sexo | Idade | Cor | Anos de Estudo | Renda | Altura |
|---|
| 0 | 11 | Feminino | 23 | Parda | 12 | 800 | 1.60381 |
| 1 | 11 | Masculino | 23 | Branca | 12 | 1150 | 1.73979 |
| 2 | 11 | Masculino | 35 | Parda | 15 | 880 | 1.76044 |
| 3 | 11 | Feminino | 46 | Branca | 6 | 3500 | 1.78316 |
| 4 | 11 | Masculino | 47 | Parda | 9 | 150 | 1.69063 |
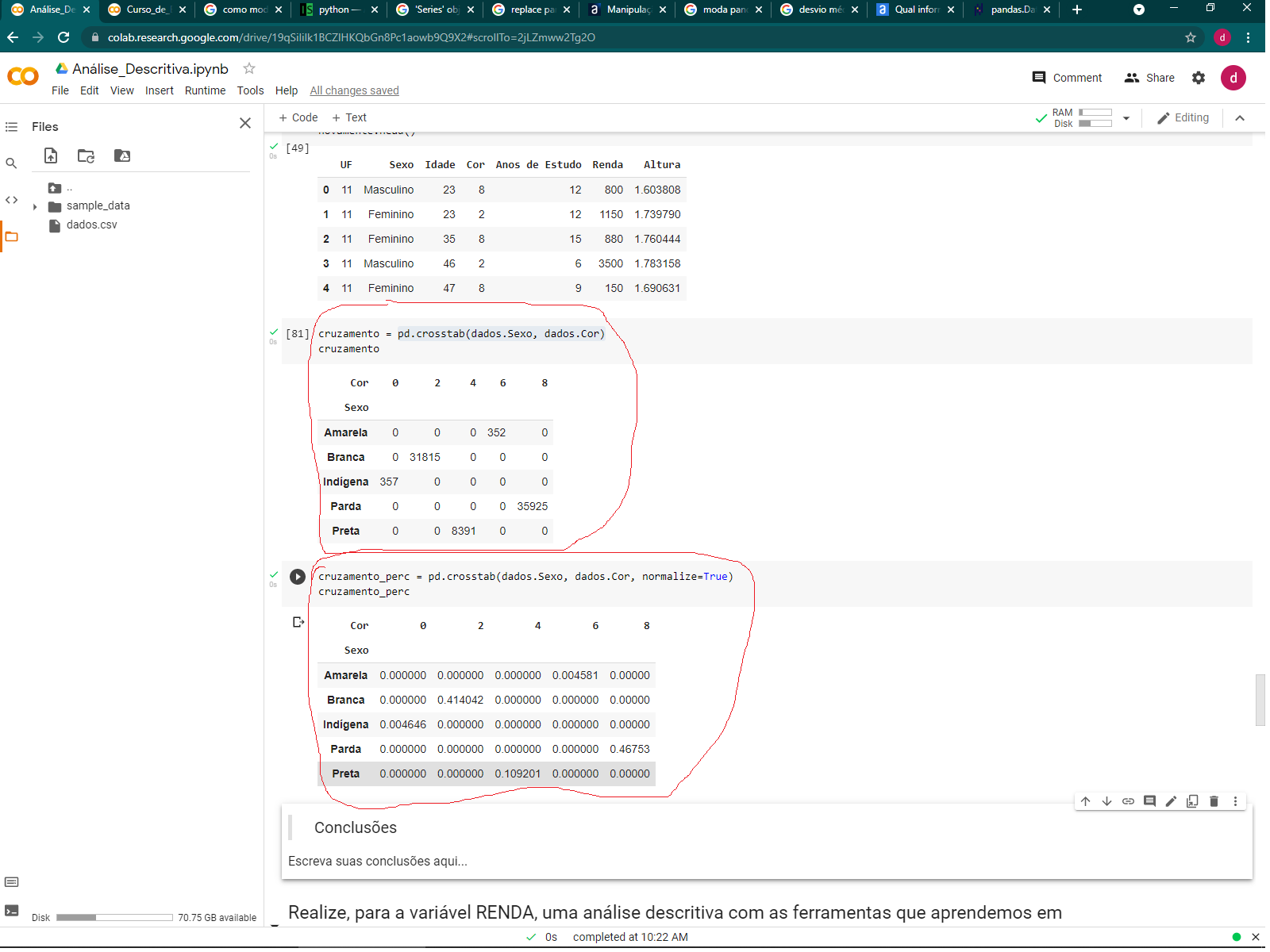
Para realizar a tabela de frequência, vou usar o código:
cruzamento = pd.crosstab(dados.Sexo, dados.Cor)
cruzamento
Que resulta em:
| Sexo | Amarela | Branca | Indígena | Parda | Preta |
|---|
| Feminino | 235 | 22194 | 256 | 25063 | 5502 |
| Masculino | 117 | 9621 | 101 | 10862 | 2889 |
E para a de porcentagens:
porcentagem = pd.crosstab(dados.Sexo, dados.Cor, normalize=True)
porcentagem
que resulta em:
| Sexo | Amarela | Branca | Indígena | Parda | Preta |
|---|
| Feminino | 0.0030583 | 0.288834 | 0.0033316 | 0.326171 | 0.0716033 |
| Masculino | 0.00152264 | 0.125208 | 0.00131442 | 0.141359 | 0.0375976 |
Espero ter ajudado!
Caso o erro persista, peço que disponibilize o notebook.
Bons estudos!