Olá Vinícius, tudo bem com você?
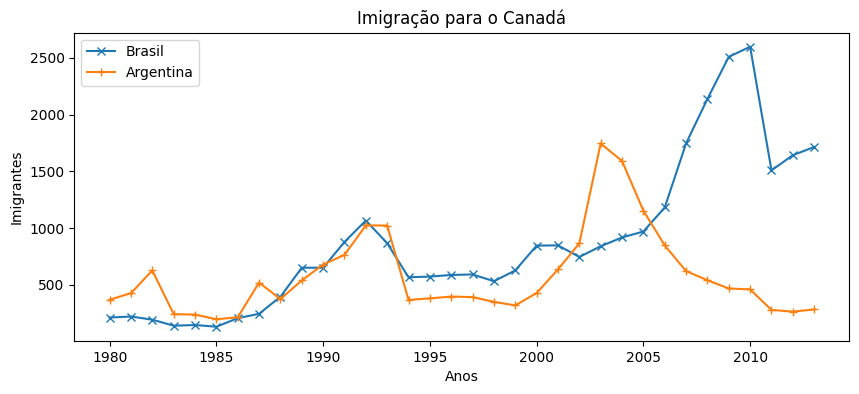
Sua solução está muito bem estruturada, parabéns. A ideia de personalizar os markers demonstra que você está explorando bem as possibilidades da Matplotlib.
Para adicionar rótulos de dados em cada ponto do gráfico, você pode usar o método plt.text(), que permite adicionar textos posicionados no gráfico, usando a seguinte sintaxe básica:
plt.text(x, y, texto, fontsize, ha, color)
Onde:
x e y definem a posição (coordenadas) onde o texto será exibidotexto é o conteúdo a ser mostrado, como valores ou rótulos- Os parâmetros
fontsize (tamanho da fonte), ha (alinhamento horizontal, como 'center') e color (cor do texto) ajudam a personalizar o rótulo
Para o seu código a implementação fica da seguinte forma:
# Adicionando rótulos de dados
for i in range(len(Dados_Brasil)):
plt.text(Dados_Brasil['Ano'][i], Dados_Brasil['Imigrantes'][i], f"{Dados_Brasil['Imigrantes'][i]}", fontsize=8, ha='center', color='blue')
for i in range(len(Dados_Argentina)):
plt.text(Dados_Argentina['Ano'][i], Dados_Argentina['Imigrantes'][i], f"{Dados_Argentina['Imigrantes'][i]}", fontsize=8, ha='center', color='green')
No código acima, estamos percorremos os dados de Brasil e Argentina com for para posicionar cada rótulo na coordenada correspondente. Deixo abaixo o seu código com essa implementação adicionada:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r"meus dados")
df.set_index("País", inplace=True)
anos = list(map(str, range(1980, 2014)))
Brasil = df.loc['Brasil', anos]
Argentina = df.loc['Argentina', anos]
Brasil_dict = {'Ano': Brasil.index.tolist(), 'Imigrantes': Brasil.values.tolist()}
Dados_Brasil = pd.DataFrame(Brasil_dict)
Argentina_dict = {'Ano': Argentina.index.tolist(), 'Imigrantes': Argentina.values.tolist()}
Dados_Argentina = pd.DataFrame(Argentina_dict)
plt.figure(figsize=(10, 4))
plt.plot(Dados_Brasil['Ano'], Dados_Brasil['Imigrantes'], label="Brasil")
plt.plot(Dados_Argentina['Ano'], Dados_Argentina['Imigrantes'], label="Argentina")
# Adicionando rótulos de dados
for i in range(len(Dados_Brasil)):
plt.text(Dados_Brasil['Ano'][i], Dados_Brasil['Imigrantes'][i], f"{Dados_Brasil['Imigrantes'][i]}", fontsize=8, ha='center', color='blue')
for i in range(len(Dados_Argentina)):
plt.text(Dados_Argentina['Ano'][i], Dados_Argentina['Imigrantes'][i], f"{Dados_Argentina['Imigrantes'][i]}", fontsize=8, ha='center', color='green')
plt.legend()
plt.title('Imigração para o Canadá')
plt.xlabel('Anos')
plt.ylabel('Imigrantes')
plt.xticks(['1980', '1985', '1990', '1995', '2000', '2005', '2010'])
plt.grid(alpha=0.3)
plt.show()

Um spoiler das próximas aulas, na atividade adicionando anotações será apresentado com detalhes sobre como você pode fazer uso do método plt.text().
Espero ter ajudado. Conte com o apoio do Fórum na sua jornada. Fico à disposição.
Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado