Tudo bem Paulo? Vou deixar a forma com que eu resolvi o problema:
Antes de tudo, vamos importar as biblotecas necessárias:
import requests
from bs4 import BeautifulSoup
Agora vamos carregar as informações da página:
r = requests.get('https://www.geekhunter.com.br/vagas')
Agora, basta criar um soup dessas informações pra que a gente possa fazer o parseamento:
soup = BeautifulSoup(r.text)
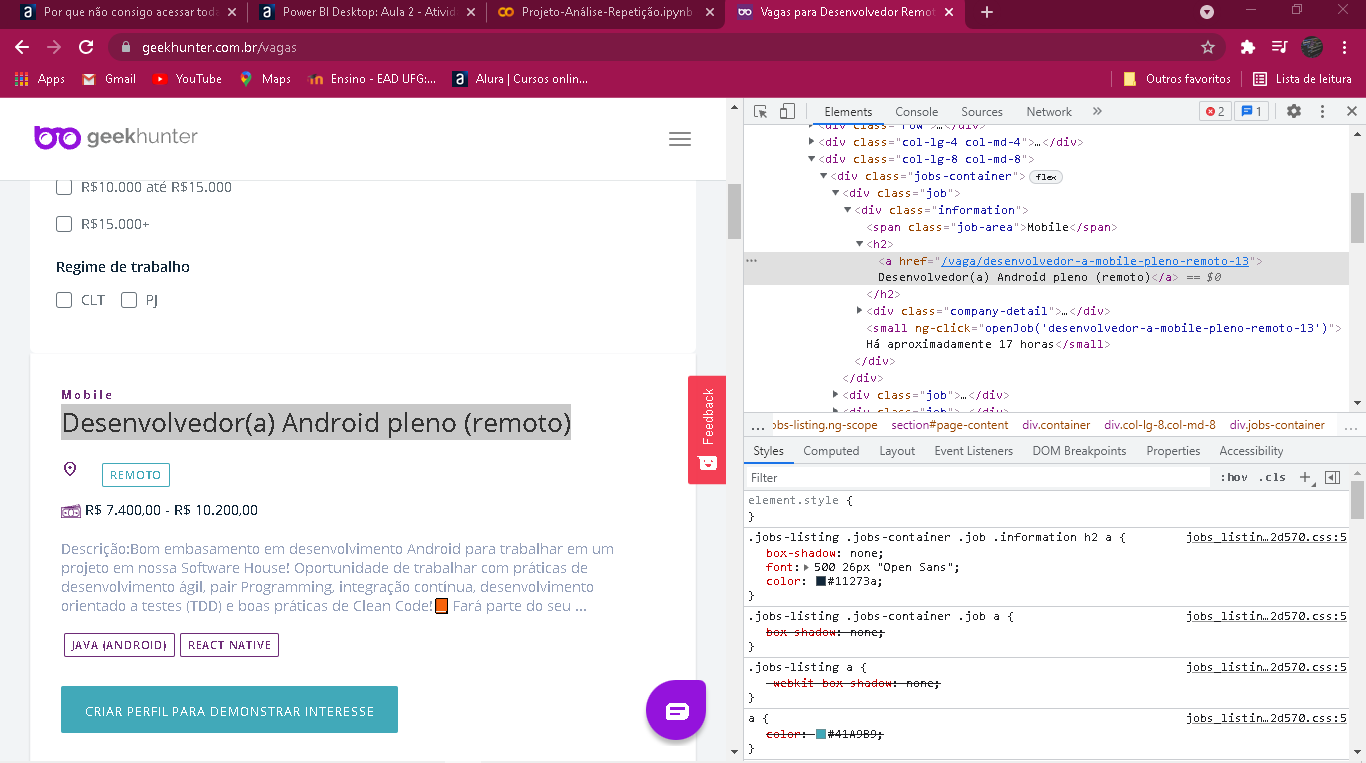
Para encontrar as informações, eu vi inspecionando os elementos HTML que eles estão organizados da seguinte maneira:
Cada vaga tem uma div chamada information, que contém todas as informações da vaga, incluindo o link que você deseja, sendo que esse link está dentro de uma tag a.
Para conseguir salvar cada vaga, vou fazer uma lista com essas tags information:
informacoes = soup.find_all('div', class_='information')
Agora, basta buscar o link que está na tag a:
link =informacoes[1].find('a')['href']
link
Para essa vaga - informações[1] - o link retornado é esse:
'/vaga/desenvolvedor-a-mobile-pleno-remoto-13'
Perceba que falta o começo da página, então devemos adicionar esse início:
link_completo = f'https://www.geekhunter.com.br{link}'
link_completo
que retorna:
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-mobile-pleno-remoto-13'
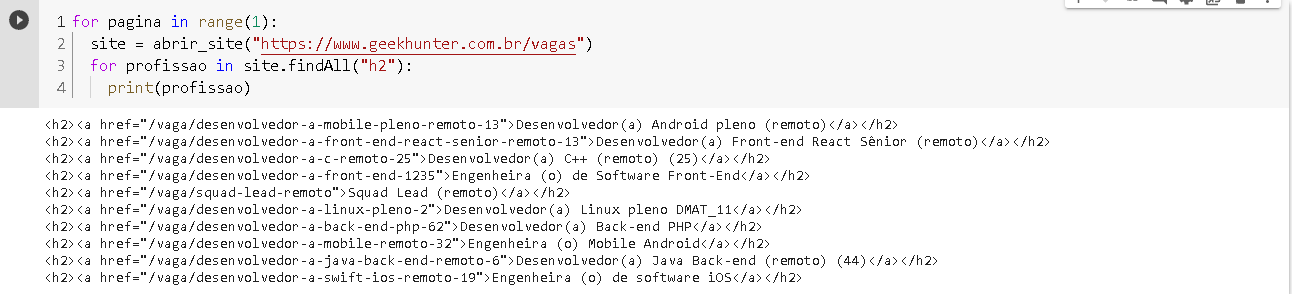
Agora vamos criar um laço que faz isso para cada uma das vagas:
links = []
for info in informacoes:
link = info.find('a')['href']
link_completo = f'https://www.geekhunter.com.br{link}'
links.append(link_completo)
Acessando links, temos uma lista de todos os links das vagas:
['https://www.geekhunter.com.br/vaga/analista-de-dados-remoto-python',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-mobile-pleno-remoto-13',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-front-end-react-senior-remoto-13',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-c-remoto-25',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-front-end-1235',
'https://www.geekhunter.com.br/vaga/squad-lead-remoto',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-linux-pleno-2',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-back-end-php-62',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-mobile-remoto-32',
'https://www.geekhunter.com.br/vaga/desenvolvedor-a-java-back-end-remoto-6']
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓.Bons Estudos!




 Ou pelo atalho + +.
Ou pelo atalho + +.