Nádia, tem como eu pegar a segunda coluna de todas as pastas e juntar em uma só pasta para que eu possa fazer minha análise?
Kamila, para fazer isso, podemos utilizar a função iloc e passarmos o índice da coluna que queremos. Por padrão, a coluna começará com o número 0 e como queremos a segunda coluna, o índice que procuramos é o índice 1. No código abaixo criei uma lista para armazenar os dados de todas as segundas colunas e utilizamos o trecho do código anterior para fazer essa captura:
import glob
import pandas as pd
from pandas import ExcelWriter
arquivos = glob.glob('Local*.xlsx')
endereco_da_pasta = 'C:/Users/nadia/Documents/Excel'
dados_da_segunda_coluna = []
for nome_arquivo in arquivos:
data = pd.read_excel(nome_arquivo)
segunda_coluna_do_arquivo = data.iloc[:,1]
dados_da_segunda_coluna.append(segunda_coluna_do_arquivo)
data.index = data['ano']
novo = data.stack()
novo.to_excel(f'{endereco_da_pasta}/{nome_arquivo}')
Após isso, percorremos esses dados da lista e colocamos em uma planilha auxiliar, onde cada aba da planilha corresponderá a segunda coluna de um arquivo, por exemplo:
for indice in range(len(dados_da_segunda_coluna)):
with ExcelWriter('comparacao_segunda_coluna.xlsx', mode='a') as writer:
dados_da_segunda_coluna[indice].to_excel(writer, sheet_name='SegundaColunaArquivo')

E por fim, criamos o arquivo final que conterá todos os resultados juntos:
resultado = pd.concat(pd.read_excel('comparacao_segunda_coluna.xlsx', sheet_name=None), ignore_index=True)
resultado.to_excel(f'{endereco_da_pasta}/resultado_segunda_coluna.xlsx')
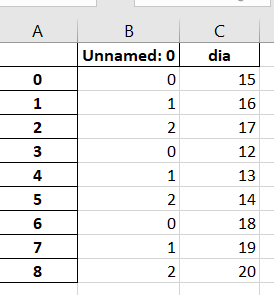
Vale ressaltar que nesse exemplo acima que o arquivo está sendo salvo com os índices de cada valor, então por exemplo: 0,1,2 corresponde aos índices do primeiro arquivo. Os próximos 0,1,2 aos índices do segundo arquivo e assim por diante.
Da forma como mostrei, você terá todos os dados brutos em um só lugar e agora decidirá o que fará com eles. Talvez seja necessário alguma reorganização, mas a parte manual de carregar o dado de cada coluna está automatizada.
Código completo:
import glob
import pandas as pd
from pandas import ExcelWriter
arquivos = glob.glob('Local*.xlsx')
endereco_da_pasta = 'C:/Users/nadia/Documents/Excel'
dados_da_segunda_coluna = []
for nome_arquivo in arquivos:
data = pd.read_excel(nome_arquivo)
segunda_coluna_do_arquivo = data.iloc[:,1]
dados_da_segunda_coluna.append(segunda_coluna_do_arquivo)
data.index = data['ano']
novo = data.stack()
novo.to_excel(f'{endereco_da_pasta}/{nome_arquivo}')
for indice in range(len(dados_da_segunda_coluna)):
with ExcelWriter('comparacao_segunda_coluna.xlsx', mode='a') as writer:
dados_da_segunda_coluna[indice].to_excel(writer, sheet_name='SegundaColunaArquivo')
resultado = pd.concat(pd.read_excel('comparacao_segunda_coluna.xlsx', sheet_name=None), ignore_index=True)
resultado.to_excel(f'{endereco_da_pasta}/resultado_segunda_coluna.xlsx')
Obs: crie um arquivo excel em branco na pasta onde está executando o código com o nome comparacao_segunda_coluna e após isso execute o código.
Qualquer dúvida é só falar, estou por aqui, tá bom?
Abraços e bons estudos!





