
Utilizei as duas formas de cálculo do desvio padrão pra a mesma base do Toy Story e Jumanji conforme abaixo:
print(notas_jumanji.nota.std(), notas_toy_story.nota.std())
print(np.std(notas_jumanji.nota), np.std(notas_toy_story.nota))para minha surpresa, os valores vieram diferentes, segue valores respectivos: 0.8817134921476455 0.8348591407114047 0.8776965532969933 0.8329153449641147
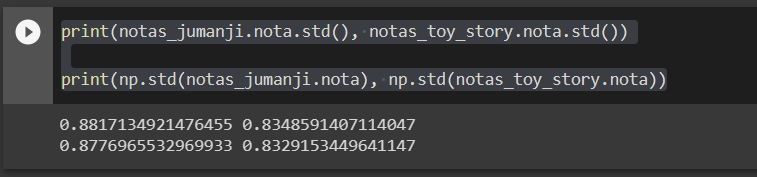
Apesar dos valores serem próximos, existe uma diferença matemática entre eles, o que me leva a pensar que existe uma diferença nos cálculos realizados pelo pandas e pelo numpy? Escrevi corretamente o código? Existe mesmo uma diferença entre os cálculos?

