Oii Lucas, tudo bem contigo?
Peço desculpas pela demora em dar um retorno.
De fato, faz sentido a sua pontuação. Acompanhando a lógica da função novo_corretor, em teoria, a palavra_corrigida sempre vai estar no vocabulário.
Dessa forma, realmente não deveria fazer diferença se contamos as palavras desconhecidas dentro ou fora do else. No entanto, ao fazermos esse teste no código vamos perceber que, quando incrementamos a variável desconhecidas fora do else, obtemos como taxa de desconhecida o valor 6.99% e quando incrementamos ela dentro do else, temos o resultado 6.45%.
Como, em teoria, não era pra essa diferença acontecer, precisamos explorar qual seria o motivo dessa diferença nos valores.
A nossa base de teste é uma lista composta por diferentes tuplas, nas quais, a primeira palavra dessas tuplas estão corretas e as segundas palavras estão erradas. Entretanto, se analisarmos a tupla que está na posição 173, vamos perceber que ela é um a caso a parte, onde temos as duas palavras escritas de forma correta:
lista_teste[173]
Resultado:
('empoderamento', 'empoderamento')
E qual o problema que isso causa?
Observe a função avaliador:
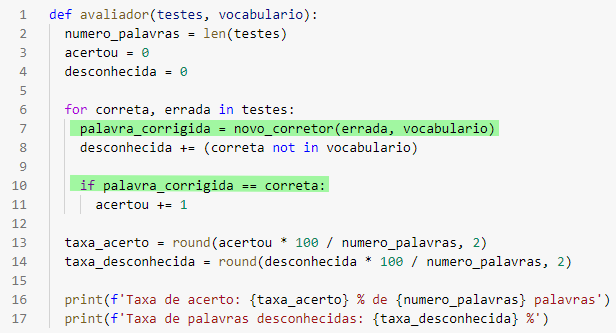
Na linha 7, quando chegarmos nas palavras da lista testes[173] vamos enviar a palavra empoderamento como uma palavra errada para o nosso corretor corrigí-la. Todavia, essa palavra não está errada de verdade, então isso vai fazer com que, independente da palavra empoderamento estar ou não no nosso vocabulário, ela seja igual a correta, entre no bloco if e que a variável acertou seja incrementada.
E, se conferirmos se essa palavra existe ou não no nosso vocabulário, vamos perceber que ela não existe:
'empoderamento' in vocabulario
Resultado:
False
Portanto, isso quer dizer que nosso corretor não conhece essa palavra, mas ela já estava correta ao ser enviada para ele. Se analisarmos a função novo_corretor, vamos perceber que na linha 5 é inicializada uma lista de possíveis palavras e a primeira palavra adicionada nessa lista é a palavra recebida pela função. Por isso ele vai "corrigir" uma palavra desconhecida e não vai cair no else:
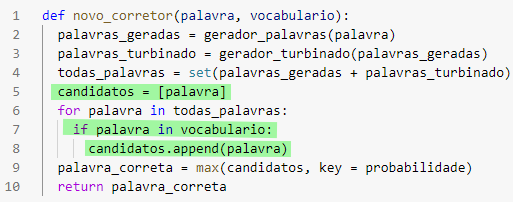
Sendo assim, podemos concluir que, em casos como esse, não necessariamente nossa palavra_corrigida estará no nosso vocabulário, uma vez que ela já foi enviada escrita de forma correta para nosso corretor.
Se nós substituirmos a segunda palavra da tupla na posição 173 da lista_teste, por uma palavra errada, como por exemplo:
lista_teste[173] = ('empoderamento', 'aempoderamento')
E, em seguida, rodarmos novamente a função avaliador, primeiro contando as desconhecidas antes do bloco if e depois executarmos de novo essa função com a variável desconhecidas dentro do bloco else vamos obter a mesma taxa de 6.99%.
Isso indica que na nossa base de dados, apenas essa tupla estava com ambas as palavras corretas. No entanto, para que não tenhamos nenhum tipo de problemas como o mostrado anteriormente, podemos concluir que é mais seguro e correto deixarmos a contagem das palavras desconhecidas antes do bloco if, para termos certeza que realmente vamos contar todas as palavras desconhecidas.
Espero que tenha conseguido te ajudar. Qualquer dúvida estou por aqui, tá bom?
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!


