Assim como comentaram anteriormente do OneHotEncoding e o pd.get_dummies, existe uma alternativa bem simples com o sklearn e que ainda possa ser implementada no Pipeline, assim o código não é prejudicado caso a base de dados sofrer alguma alteração.
# Lendo o arquivo
df = pd.read_csv('stackoverflow_perguntas.csv')
# Separando as tags
split_tags_series = df['Tags'].apply(str.split)
from sklearn.preprocessing import MultiLabelBinarizer
mlb = MultiLabelBinarizer()
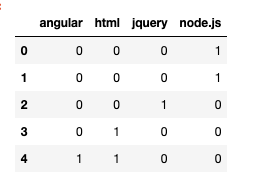
# Visualizando o que o MultiLabelBinarizer fará dentro do pipeline
tag_counts = pd.DataFrame(
mlb.fit_transform(split_tags_series),
columns=mlb.classes_,
index=df.index)
tag_counts.head()