
Bom Dia, todos bem?
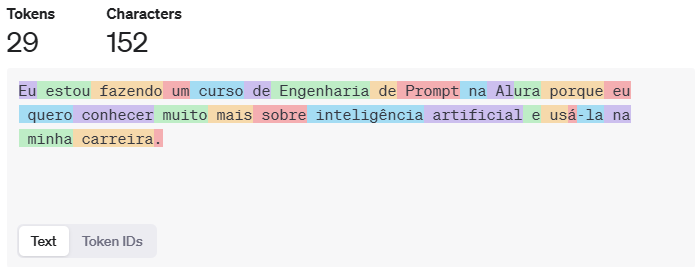
Estou na página do Tokenizer da OpenAi e digitei a mesma frase que o Fabricio mostrou em aula, e percebi que a quantidade de tokens ficou diferente.
Sabem me dizer o porque isso acontece? Seria porque o modelo foi melhor treinado em português desde a data em que a aula foi gravada até o dia de hoje?
No exemplo da aula 37 tokens e 152 characteres. Abaixo segue o que retornou pra mim, usando a mesmíssima frase.
 Obrigada desde já!
Obrigada desde já!

