TENHO UMA DUVIDA ATÉ NO MOMENTO TODOS OS valores batiam com o da aula mas nesta foi diferente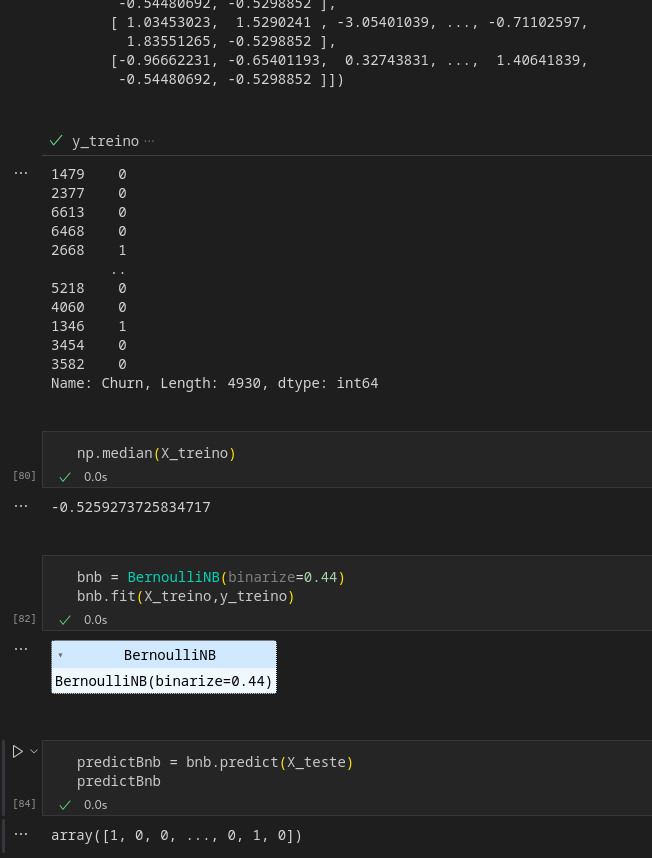
#imports
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import BernoulliNB
#data
data = pd.read_csv("Customer-Churn.csv")
data.head()
#dataTransform
TranslateDictionary = {
"Sim":1,
"Nao":0
}
modifiedData = data[["Conjuge","Dependentes","TelefoneFixo","PagamentoOnline","Churn"]].replace(TranslateDictionary)
modifiedData.head()
#dummieTransform
dataDummie = pd.get_dummies(data.drop(["Conjuge","Dependentes","TelefoneFixo","PagamentoOnline","Churn"],axis=1))
#dataDummie.head()
finalData = pd.concat([ modifiedData,dataDummie],axis=1)
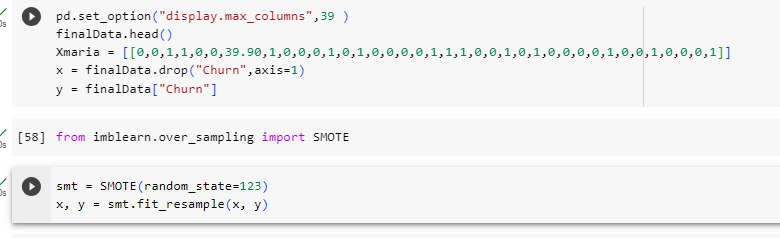
pd.set_option("display.max_columns",39 )
finalData.head()
Xmaria = [[0,0,1,1,0,0,39.90,1,0,0,0,1,0,1,0,0,0,0,1,1,1,0,0,1,0,1,0,0,0,0,1,0,0,1,0,0,0,1]]
x = finalData.drop("Churn",axis=1)
y = finalData["Churn"]
#standardized
stand = StandardScaler()
standardizedX = stand.fit_transform(x)
standardizedX[0]
standardizedMaria = stand.transform(pd.DataFrame(Xmaria, columns= x.columns))
standardizedMaria
#euclidean distance
a = standardizedMaria
b = standardizedX[0]
euclideanDistance = np.sum(np.square(a-b))
np.sqrt(euclideanDistance)
X_treino, X_teste, y_treino, y_teste = train_test_split(standardizedX, y, test_size=0.3, random_state=123)
knn = KNeighborsClassifier(metric='euclidean')
knn.fit(X_treino, y_treino)
predito_knn = knn.predict(X_teste)
predito_knn
X_treino
y_treino
np.median(X_treino)
bnb = BernoulliNB(binarize=0.44)
bnb.fit(X_treino,y_treino)
predictBnb = bnb.predict(X_teste)
predictBnb