Oii Danival! Tudo tranquilo?
Peço desculpas pela demora em dar um retorno.
No caso do arquivo json utilizado no curso, o listings é uma lista de arquivos json, que se encontra tanto na coluna “normal” quanto na coluna “highlights”. Observe:
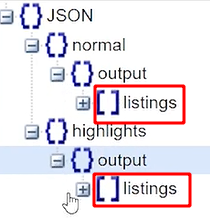
Quando utilizamos o json_normalize e passamos apenas o parâmetro data, esse método irá expandir nosso arquivo json, criando colunas. No entanto, ele só expande enquanto temos arquivos json, ou seja, se ele se deparar com um arquivo que não seja um json (dicionário), como uma lista, um número ou uma string, ele para de navegar nesse arquivo e já transforma, até o ponto onde ele expandiu, em uma coluna.
No caso do arquivo da aula, então, ao fazer dados_normal = pd.json_normalize(data = dados.normal) o método expande o arquivo json normal > output e para de expandir em listings, já que essa variável é uma lista. Deixando o dataframe assim:
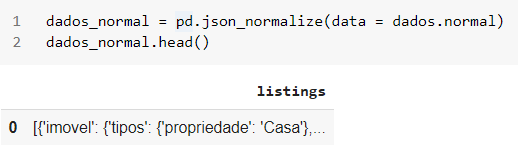
Sendo assim, para resolver isso, e fazer com que o método json_normalize também expanda essa lista, utilizamos o parâmetro record_path e passamos o nome da lista. Assim o método vai entender que listings não é um json, mas que também desejamos expandi-la.
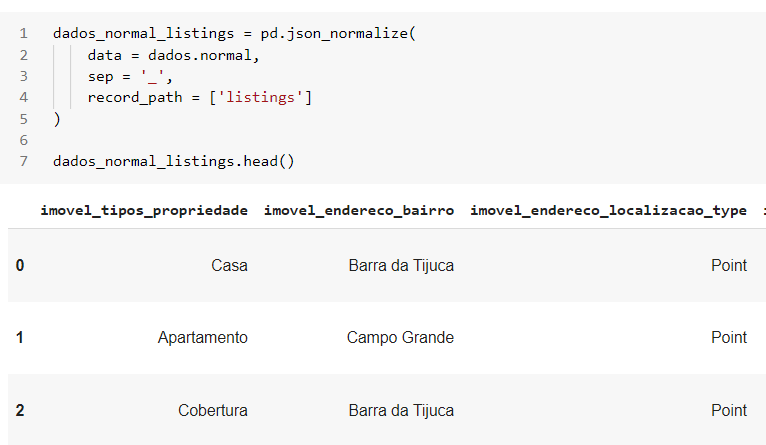
Dessa forma, podemos perceber que esse método vai variar para cada caso. Tudo vai depender de como seu arquivo json está estruturado. Então, pode ser que seja necessário utilizar o parâmetro record_path especificando uma variável que não seja json, ou caso você tenha um arquivo json que realmente tenha apenas arquivos json, nem seja necessário especificar tal parâmetro.
Espero que tenha conseguido ajudá-lo! Qualquer dúvida estamos à disposição :)
Bons estudos!


