Opa. Olá, Vivian.
No exemplo que eu passei na resposta, eu considerei a variável alunos_grupo como sendo apenas uma lista de valores. Não considerei que era um objeto do tipo groupby. E por conta disso, a saída de quando usamos o mean() ainda é uma Series do Pandas, que se encaixa nos exemplos que comentei que funcionaria o uso do round(). Desse modo o exemplo que passei já não se aplica.
Vamos lá.
Uma das maneiras de criar um DataFrame com um nome de coluna especificado, é passando um dicionário, onde a chave do dicionário será o nome da coluna, e o valor, será o conteúdo da coluna no DataFrame. Então podemos fazer:
import pandas as pd
alunos = pd.DataFrame({'Nome': ['Ary', 'Cátia', 'Denis', 'Beto', 'Bruna', 'Dara', 'Carlos', 'Alice'],
'Sexo': ['M', 'F', 'M', 'M', 'F', 'F', 'M', 'F'],
'Idade': [15, 27, 56, 32, 42, 21, 19, 35],
'Notas': [7.5, 2.5, 5.0, 10, 8.2, 7, 6, 5.6],
'Aprovado': [True, False, False, True, True, True, False, False]},
columns = ['Nome', 'Idade', 'Sexo', 'Notas', 'Aprovado'])
alunos_grupo = alunos.groupby('Sexo')
alunos_media = pd.DataFrame({'Notas Médias': alunos_grupo['Notas'].mean().round(2)})
alunos_media
Como a nossa pandas.Series tem um nome que veio da operação do groupby(), se não adicionarmos nada, a função pandas.DataFrame() reutiliza o nome da Series como nome da coluna. E se nós sabemos esse nome, também podemos usar o método rename(). Exemplo:
import pandas as pd
alunos = pd.DataFrame({'Nome': ['Ary', 'Cátia', 'Denis', 'Beto', 'Bruna', 'Dara', 'Carlos', 'Alice'],
'Sexo': ['M', 'F', 'M', 'M', 'F', 'F', 'M', 'F'],
'Idade': [15, 27, 56, 32, 42, 21, 19, 35],
'Notas': [7.5, 2.5, 5.0, 10, 8.2, 7, 6, 5.6],
'Aprovado': [True, False, False, True, True, True, False, False]},
columns = ['Nome', 'Idade', 'Sexo', 'Notas', 'Aprovado'])
alunos_grupo = alunos.groupby('Sexo')
alunos_media = pd.DataFrame(alunos_grupo['Notas'].mean().round(2)).rename(columns={'Notas': 'Notas Médias'})
alunos_media
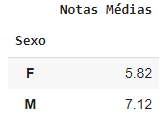
E ambos resultam na seguinte saída:
| Sexo | Notas Médias |
|---|
| F | 5.82 |
| M | 7.12 |
Se ainda tiver alguma dúvida, estou por aqui. Ótimos estudos e grande abraço!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!



 )
) )
) )
)