Encontrei a resposta!
O problema é que cada sistema operacional trata a quebra de linha de uma forma!
Ao abrir um arquivo, no Python, existe um parâmetro chamado newline. Esse parâmetro indica como as quebras de linha serão tratadas. Ou seja, se haverá conversão ou não da quebra de linha.
Esse parâmetro pode assumir 5 valores: (None, "", "\n", "\r", "\r\n")
| Parâmetro | Conversão da quebra de linha |
|---|
| None | Valor default. A quebra de linha do texto será convertida, ao escrever no arquivo, para a quebra de linha do sistema atual |
| "" | Não haverá nenhuma conversão de quebra de linha |
| \n | A quebra de linha será convertida na quebra de linha padrão do Linux |
| \r | A quebra de linha será convertida na quebra de linha padrão do Mac OS |
| \r\n | A quebra de linha será convertida na quebra de linha padrão do Windows. |
No meu caso, como o sistema é Windows, se a quebra de linha for None...
arquivo_contatos = open('dados/contatos-escrita.csv', encoding='latin_1', mode='w+')
... o "\n" é convetido para "\r\n", conforme a saída do arquivo:
b'11,Carol,carol@carol.com.br\r\n12,Ana,ana@ana.com.br\r\n13,Tais,tais@tais.com.br\r\n14,Felipe,felipe@felipe.com.br\r\n'
Se a chamada passar o newline='\r'...
arquivo_contatos = open('dados/contatos-escrita.csv', encoding='latin_1', mode='w+', newline="\r")
... o resultado é:
b'11,Carol,carol@carol.com.br\r12,Ana,ana@ana.com.br\r13,Tais,tais@tais.com.br\r14,Felipe,felipe@felipe.com.br\r'
No meu caso, como não houve nenhuma especificação, o valor default foi passado:
arquivo_contatos = open('dados/contatos-escrita.csv', encoding='latin_1', mode='w+')
Isso resultou num arquivo em que todos os \n foram trocados por \r\n, ou seja: aumentando UM caracter em cada linha.
A linha, que deveria estar assim:
b'11,Carol,carol@carol.com.br\n12,Ana,ana@ana.com.br\n13,Tais,tais@tais.com.br\n14,Felipe,felipe@felipe.com.br\n'
Foi gravada assim:
# V - A posição 28 deveria ser aqui, '1'...
b'11,Carol,carol@carol.com.br\r\n12,Ana,ana@ana.com.br\r\n13,Tais,tais@tais.com.br\r\n14,Felipe,felipe@felipe.com.br\r\n'
# ^ ... mas ela está aqui, no '\n'
Dessa forma, a posição 28 não é ocupada pelo primeiro caracter da segunda linha, o '1', mas pelo '\n' na primeira linha.
Ao executar a substituição...
arquivo_contatos.write('12,Ana,ana@ana.com.br\n'.upper())
... a segunda linha começa no lugar do '\n' da primeira linha. Ao invés de substituir...
b'12,Ana,ana@ana.com.br\r\n'
por
b'12,ANA,ANA@ANA.COM.BR\r\n`
O que ocorre é a substituição de
b'\n12,Ana,ana@ana.com.br\r'
por
b'12,ANA,ANA@ANA.COM.BR\r\n'
Ou seja:
b'11,Carol,carol@carol.com.br\r\n12,Ana,ana@ana.com.br\r\n13,Tais,tais@tais.com.br\r\n14,Felipe,felipe@felipe.com.br\r\n'
vira
b'11,Carol,carol@carol.com.br\r12,ANA,ANA@ANA.COM.BR\r\n\n13,Tais,tais@tais.com.br\r\n14,Felipe,felipe@felipe.com.br\r\n'
O que, no fim, gera o arquivo
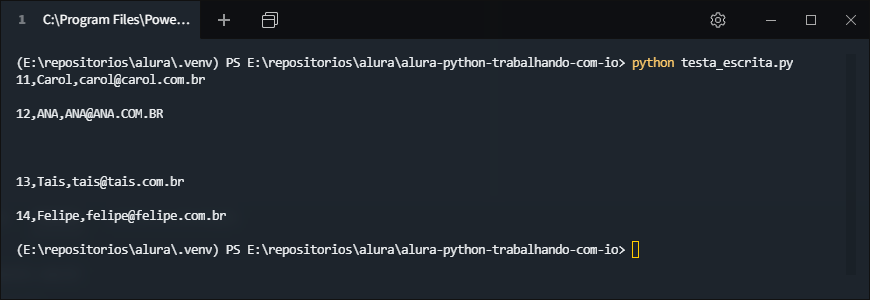
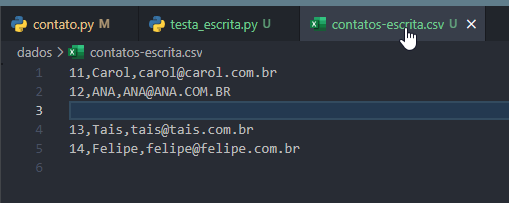
11,Carol,carol@carol.com.br
12,ANA,ANA@ANA.COM.BR
13,Tais,tais@tais.com.br
14,Felipe,felipe@felipe.com.br
Portanto, se for necessário usar uma quebra de linha em específico, ao lidar com arquivos, e o programa for executado em mais de um sistema operacional, devemos garantir o comportamento especificando o parâmetro newline:
arquivo_contatos = open('dados/contatos-escrita.csv', encoding='latin_1', mode='w+', newline="")
Espero que isso possa ajudar alguém que passar pelo mesmo problema, no futuro. :D