Oii Ana, desculpe pela demora em retornar.
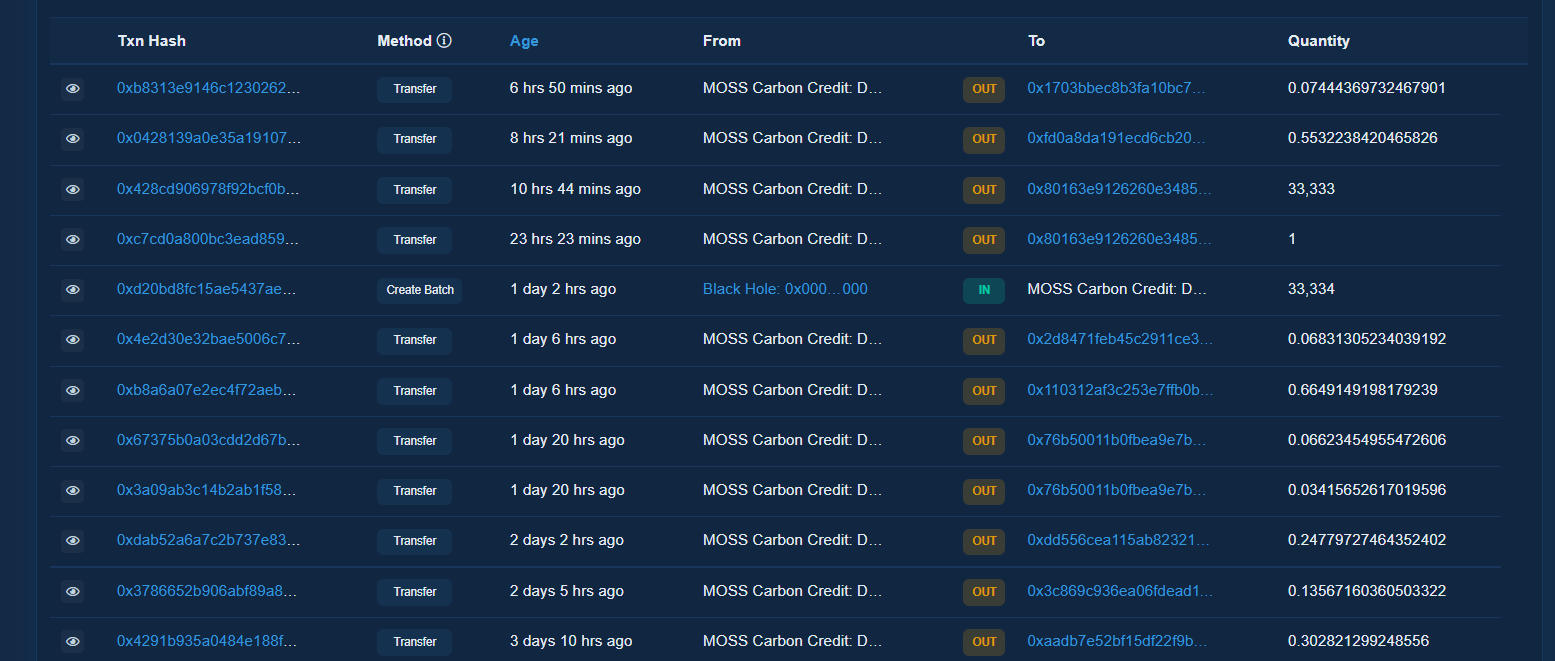
Na verdade, a classe responsável por retornar o número de elementos da página é a page-link, como mostro na imagem abaixo:

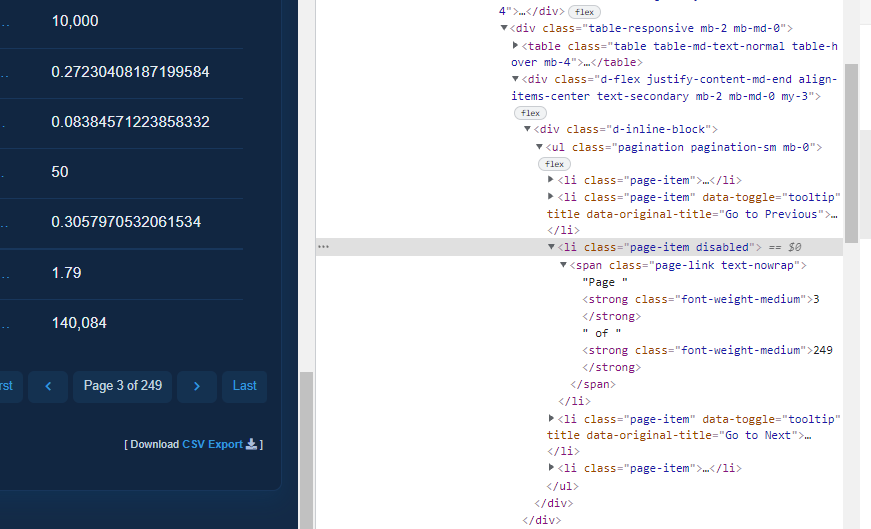
Se pegarmos esse dado, virá o texto "Page 1 of 249", nisso, como o nosso objetivo é saber a quantidade total de páginas que teremos que percorrer, o número que nos interessa é o valor 249, certo? Nisso, podemos recorrer a um recurso do Python para separar essa string por espaços e pegarmos o último elemento dessa lista. Podemos fazer isso através da função split e como queremos o último elemento utilizaremos o índice -1, como mostro abaixo:
texto = "Page 1 of 249"
texto.split(' ')
# resultado: ['Page', '1', 'of', '249']
texto.split(' ')[-1]
# resultado: '249'
Após pegar a quantidade de páginas que teremos que percorrer, o único parâmetro que devemos mudar na URL do iframe é o do número de páginas, caracterizado pelo p, veja que na URL que mostro abaixo temos p=1 que indica que estamos na primeira página:
https://etherscan.io//token/generic-tokentxns2?m=normal&contractAddress=0xfc98e825a2264d890f9a1e68ed50e1526abccacd&a=0x70d5eadcb367bcf733fc98b441def1c7c5eec187&sid=0c2e52e2744d41ceb6fdc26c0bfddeaa&p=1
Com base nisso, o código para percorrer as páginas e capturar todos os dados ficará da seguinte forma:
from selenium import webdriver
from bs4 import BeautifulSoup
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import pandas as pd
import time
url_principal = ("https://etherscan.io/token/0xfc98e825a2264d890f9a1e68ed50e1526abccacd?a=0x70d5eadcb367bcf733fc98b441def1c7c5eec187")
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(url_principal)
resp = driver.page_source
soup = BeautifulSoup(resp, 'html')
link_iframe_tabela = soup.find('iframe', id='tokentxnsiframe')['src']
url_base = "https://etherscan.io"
url_dados_tabela = f'{url_base}{link_iframe_tabela}'
driver.find_element_by_tag_name('body').send_keys(Keys.COMMAND + 't')
time.sleep(5)
driver.get(url_dados_tabela)
dados = driver.page_source
soup = BeautifulSoup(dados, 'html.parser')
quantidade_total_de_paginas = soup.find('span', class_='page-link text-nowrap')
quantidade_total_de_paginas = int(quantidade_total_de_paginas.text.split(' ')[-1])
url_dados_tabela = url_dados_tabela.split('&p=1')[0]
dataframes = []
for pagina in range(1, quantidade_total_de_paginas+1):
time.sleep(2)
driver.get(f'{url_dados_tabela}&p={pagina}')
dados = driver.page_source
tabela = pd.read_html(dados)[0]
tabela.drop(['Unnamed: 0', 'Unnamed: 8'], axis = 1, inplace=True)
tabela.rename({'Unnamed: 3': 'Updated to', 'Unnamed: 5': 'Type'}, axis=1, inplace=True)
dataframes.append(tabela)
print(dataframes)
todos_os_dados = pd.concat(dataframes)
todos_os_dados.reset_index(inplace=True, drop=True)
print(todos_os_dados)
driver.close()
No código acima abrirmos todas as páginas e salvamos o resultado do em uma lista de dataframes e após isso juntamos essas informações em um único dataframe utilizando o pd.concat.
O resultado ficará da seguinte forma:

Veja que o dataframe final informa que temos 6224 linhas e esse valor é exatamente a quantidade de transações que há na página.

Um detalhe é que como percorremos muitas páginas, o código tem uma tendência a uma demora na execução. Em minha máquina tive uma média de 15 minutos de execução. Pode parecer muito, mas é um tempo esperado, uma vez que temos muitos dados para capturar.
Um observação importante, é que o site fornece a opção de exportar os dados como csv, que fica no final da página principal:

Logo em seguida abrirá uma tela para que você escolha a data das informações que é capaz de exportar os 5.000 primeiros registros:

Após selecionar as datas um arquivo .csv será gerado e você poderá transformar esses dados em um dataframe ou até mesmo analisar via excel de uma forma simples e rápida. Então, temos também essa opção, que dependendo do seu caso de uso pode vir a seu favor em algum momento.
Fico à disposição.
Grande abraço!