votos2 = pd.DataFrame(
{
"PARTIDO": [
"PT", "PT", "PT",
"PSDB", "PSDB", "PSDB",
"AVANTE", "AVANTE", "AVANTE"
],
"CARGO": ["Prefeito", "Vereador", "Deputado", "Prefeito", "Vereador", "Deputado", "Prefeito", "Vereador", "Deputado"],
"VOTOS": [3000, 2300, 5000, 4321, 3546, 8456, 2467, 2348, 4523],
}
)
votos2_pivot = votos2.pivot(index='PARTIDO', columns='CARGO', values='VOTOS')
votos2_pivot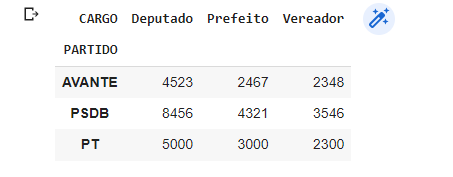
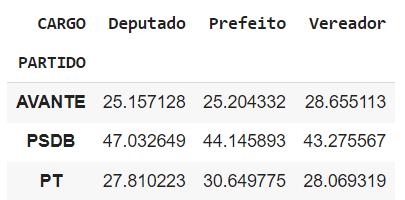
percent = pd.crosstab(votos2_pivot['PARTIDO'], votos2_pivot['CARGO'], normalize=True) * 100
percentErro:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3360 try:
-> 3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
4 frames
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas/_libs/hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 'PARTIDO'
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/pandas/core/indexes/base.py in get_loc(self, key, method, tolerance)
3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
-> 3363 raise KeyError(key) from err
3364
3365 if is_scalar(key) and isna(key) and not self.hasnans:
KeyError: 'PARTIDO'