
oi pessoal, tudo bem?
Ao tentar mapear a coluna vendido o arquivo me devolveu a informação NaN, como na figura:
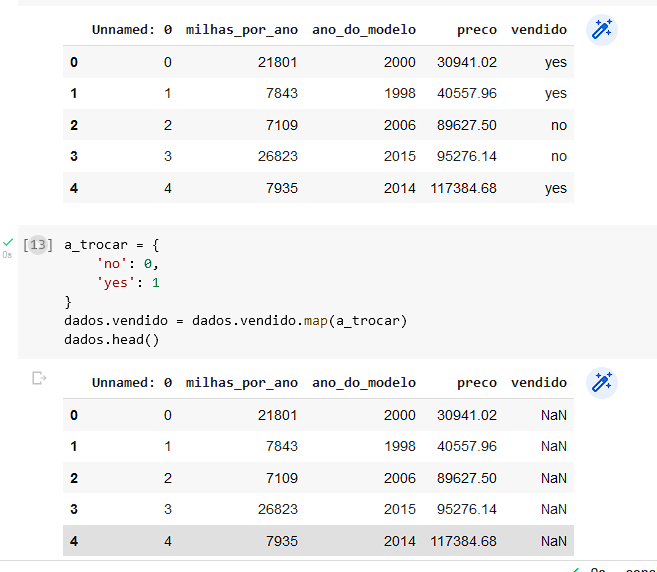
Meu código para averiguarem se há algum erro, mas não encontrei nada estranho.
import pandas as pd
uri = 'https://gist.githubusercontent.com/guilhermesilveira/4d1d4a16ccbf6ea4e0a64a38a24ec884/raw/afd05cb0c796d18f3f5a6537053ded308ba94bf7/car-prices.csv'
dados = pd.read_csv(uri)
dados.head()
a_renomear = {
'mileage_per_year' : 'milhas_por_ano',
'model_year' : 'ano_do_modelo',
'price' : 'preco',
'sold' : 'vendido'
}
dados = dados.rename(columns=a_renomear)
dados.head()
a_trocar = {
'no': 0,
'yes': 1
}
dados.vendido = dados.vendido.map(a_trocar)
dados.head()
