dataset .select('*') .na .fill(0) .show()
Na própria visualização ainda continua aparecendo os valores nulos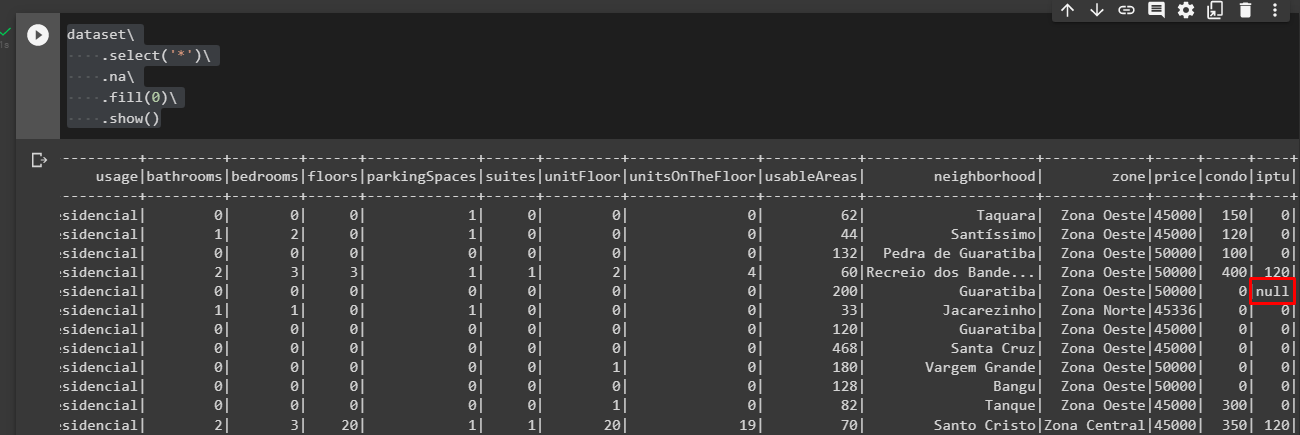
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

dataset .select('*') .na .fill(0) .show()
Na própria visualização ainda continua aparecendo os valores nulos


Também estou com mesmo problema a função não está mudando os valores da coluna. É o mesmo código
dataset\
.select('*')\
.na\
.fill(0)\
.show() Resultado>
+---------------+-----------+-----------+---------+--------+------+-------------+------+---------+---------------+-----------+--------------------+------------+-----+-----+----+
| customerID| unit| usage|bathrooms|bedrooms|floors|parkingSpaces|suites|unitFloor|unitsOnTheFloor|usableAreas| neighborhood| zone|price|condo|iptu|
+---------------+-----------+-----------+---------+--------+------+-------------+------+---------+---------------+-----------+--------------------+------------+-----+-----+----+
|775564-BOJSMVON| Outros|Residencial| 0| 0| 0| 1| 0| 0| 0| 62| Taquara| Zona Oeste|45000| 150| 0|
|660895-AUENKNYY|Apartamento|Residencial| 1| 2| 0| 1| 0| 0| 0| 44| Santíssimo| Zona Oeste|45000| 120| 0|
|751522-JESYFEQL| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 132| Pedra de Guaratiba| Zona Oeste|50000| 100| 0|
|568886-ZIBFOMCC|Apartamento|Residencial| 2| 3| 3| 1| 1| 2| 4| 60|Recreio dos Bande...| Zona Oeste|50000| 400| 120|
|526755-OBLTYTEN| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 200| Guaratiba| Zona Oeste|50000| 0|null|
|792086-NWNQTDYL|Apartamento|Residencial| 1| 1| 0| 1| 0| 0| 0| 33| Jacarezinho| Zona Norte|45336| 0| 0|
|339622-MNZGLKTZ| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 120| Guaratiba| Zona Oeste|45000| 0| 0|
|952338-SVULQMXR| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 468| Santa Cruz| Zona Oeste|45000| 0| 0|
|570439-LDICQOXZ| Outros|Residencial| 0| 0| 0| 0| 0| 1| 0| 180| Vargem Grande| Zona Oeste|50000| 0| 0|
|684023-YTBNKLLO| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 128| Bangu| Zona Oeste|50000| 0| 0|
|629412-VKUMMAVR| Outros|Residencial| 0| 0| 0| 0| 0| 1| 0| 82| Tanque| Zona Oeste|45000| 300| 0|
|951104-MACIAPIS|Apartamento|Residencial| 2| 3| 20| 1| 1| 20| 19| 70| Santo Cristo|Zona Central|45000| 350| 120|
|375665-GHMFEZXX|Apartamento|Residencial| 2| 3| 20| 1| 1| 20| 19| 70| Santo Cristo|Zona Central|50000| 350| 120|
|441711-LRTWHRUA|Apartamento|Residencial| 1| 1| 0| 0| 0| 2| 0| 37| Pedra de Guaratiba| Zona Oeste|50000| 0| 0|
|221946-ENAQETGD| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 120| Guaratiba| Zona Oeste|45020| 0| 0|
|023787-PTASXXTL| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 120| Guaratiba| Zona Oeste|45040| 0| 0|
|385687-SWOBLUWG| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 150| Santa Cruz| Zona Oeste|45000| 0| 0|
|037953-VZOABKON|Apartamento|Residencial| 1| 2| 0| 1| 0| 0| 0| 30| Coelho Neto| Zona Norte|45000| null| 0|
|913561-GIAMXOYU| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 128| Guaratiba| Zona Oeste|45000| 0| 0|
|511928-EYKXPKBU| Outros|Residencial| 0| 0| 0| 0| 0| 0| 0| 120| Guaratiba| Zona Oeste|45070| 0| 0|Bruno, bom dia.
Eu encontrei nosso erro.
Anteriormente nos não tinhamos salvado nossas alterações no dataset quando transformamos os dados das colunas em DoubleType. e tem que salvar por que conforme verifique na documentação da pyspark.
Roda o código salavando o dataset com as alterações da colunas e depois roda o código fill
dataset = dataset\
.withColumn('usableAreas', dataset['usableAreas'].cast(IntegerType())) \
.withColumn('price', dataset['price'].cast(DoubleType())) \
.withColumn('condo', dataset['condo'].cast(DoubleType())) \
.withColumn('iptu', dataset['iptu'].cast(DoubleType()))
dataset.printSchema()